
Something I’ve been thinking about a lot lately is how much information we really convey with emoji. I was recently at the 1st International Workshop on Emoji Understanding and Applications in Social Media and one theme that stood out to me from the papers was that emoji tend to be used more to communicate social meaning (things like tone and when a conversation is over) than semantics (content stuff like “this is a dog” or “an icecream truck”).
I’ve been itching to apply an information theoretic approach to emoji use for a while, and this seemed like the perfect opportunity. Information theory is the study of storing, transmitting and, most importantly for this project, quantifying information. In other words, using an information theoretic approach we can actually look at two input texts and figure out which one has more information in it. And that’s just what we’re going to do: we’re going to use a measure called “entropy” to directly compare the amount of information in text and emoji.
What’s entropy?
Shannon entropy is a measure of how much information there is in a sequence. Higher entropy means that there’s more uncertainty about what comes next, while lower entropy means there’s less uncertainty. (Mathematically, entropy is always less than or the same as log2(n), where n is the total number of unique characters. You can learn more about calculating entropy and play around with an interactive calculator here if you’re curious.)
So if you have a string of text that’s just one character repeated over and over (like this: 💀💀💀💀💀) you don’t need a lot of extra information to know what the next character will be: it will always be the same thing. So the string “💀💀💀💀💀” has a very low entropy. In this case it’s actually 0, which means that if you’re going through the string and predicting what comes next, you’re always going to be able to guess what comes next becuase it’s always the same thing. On the other hand, if you have a string that’s made up of four different characters, all of which are equally probable (like this:♢♡♧♤♡♧♤♢), then you’ll have an entropy of 2.
TL;DR: The higher the entropy of a string the more information is in it.
Experiment
Hypothesis
We do have some theoretical maximums for the entropy text and emoji. For text, if the text string is just randomly drawn from the 128 ASCII characters (which isn’t how language works, but this is just an approximation) our entropy would be 7. On the other hand, for emoji, if people are just randomly using any emoji they like from the set of emoji as of June 2017, then we’d expect to see an entropy of around 11.
So if people are just using letters or emoji randomly, then text should have lower entropy than emoji. However, I don’t think that’s what’s happening. My hypothesis, based on the amount of repetition in emoji, was that emoji should have lower entropy, i.e. less information, than text.
Data
To get emoji and text spans for our experiment I used four different datasets: three from Twitter and one from YouTube.
- Twitter: Russian Troll Tweets: 200,000 malicious-account tweets captured by NBC
- Twitter: 24 thousand tweets later: 2017 tweets from incubators and accelerators
- Twitter: Customer Support on Twitter: Over 3 million tweets and replies from the biggest brands on Twitter
- YouTube: Trending YouTube Video Statistics and Comments: Daily statistics (views, likes, category, comments+) for trending YouTube videos
I used multiple datasets for a couple reasons. First, becuase I wanted a really large dataset of tweets with emoji, and since only between 0.9% and 0.5% of tweets from each Twitter dataset actually contained emoji I needed to case a wide net. And, second, because I’m growing increasingly concerned about genre effects in NLP research. (Like, a lot of our research is on Twitter data. Which is fine, but I’m worried that we’re narrowing the potential applications of our research becuase of it.) It’s the second reason that led me to include YouTube data. I used Twitter data for my initial exploration and then used the YouTube data to validate my findings.
For each dataset, I grabbed all adjacent emoji from a tweet and stored them separately. So this tweet:
Love going to ballgames! ⚾🌭 Going home to work in my garden now, tho 🌸🌸🌸🌸
Has two spans in it:
Span 1: ⚾🌭
Span 2: 🌸🌸🌸🌸
All told, I ended up with 13,825 tweets with emoji and 18,717 emoji spans of which only 4,713 were longer than one emoji. (I ignored all the emoji spans of length one, since they’ll always have an entropy of 0 and aren’t that interesting to me.) For the YouTube comments, I ended up with 88,629 comments with emoji, 115,707 emoji spans and 47,138 spans with a length greater than one.
In order to look at text as parallel as possible to my emoji spans, I grabbed tweets & YouTube comments without emoji. For each genre, I took a number of texts equal to the number of spans of length > 1 and then calculated the character-level entropy for the emoji spans and the texts.
Analysis
First, let’s look at Tweets. Here’s the density (it’s like a smooth histogram, where the area under the curve is always equal to 1 for each group) of the entropy of an equivalent number of emoji spans and tweets.
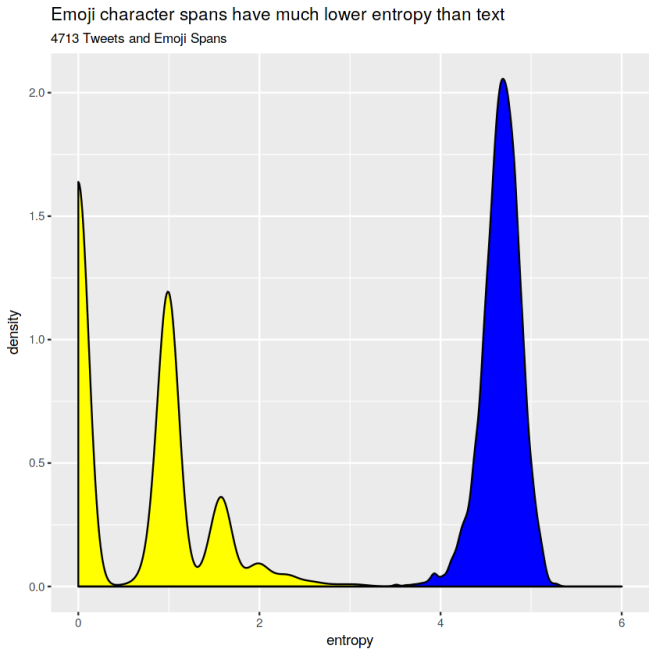
- Text has a much high character-level entropy than emoji. For text, the mean and median entropy are both around 5. For emoji, there is a multimodal distribution, with the median entropy being 0 and also clusters around 1 and 1.5.
It looks like my hypothesis was right! At least in tweets, text has much more information than emoji. In fact, the most common entropy for an emoji span is 0: which means that most emoji spans with a length greater than one are just repititons of the same emoji over and over again.
But is this just true on Twitter, or does it extend to YouTube comments as well?

The YouTube data, which we have almost ten times more of, corroborates the earlier finding: emoji spans are less informative, and more repetitive, than text.
Which emoji were repeated the most/least often?
Just in case you were wondering, the emoji most likely to be repeated was the skull emoji, 💀. It’s generally used to convey strong negative emotion, especially embarrassment, awkwardness or speechlessness, similar to “ded“.
OMFFFFFFFFFG……….how you gonna put me on blast like that @Oreo!!!!
Hahahhaha! 💀💀💀💀💀🤣😂 https://t.co/eJ1igiqJ9W
— Jaremi Carey (@PhiPhiOhara) July 5, 2018
The least likely was the right-pointing arrow (▶️), which is usually used in front of links to videos.
What are we naming the @arianagrande + @nickiminaj super group?
1️⃣ Nickari
2️⃣ Aricki
3️⃣ Minajagrande
4️⃣ GranajWatch their video #TheLightIsComing now. 💡💡
▶️https://t.co/nwLHtZ2V86pic.twitter.com/aj6RjI1IRE— Vevo (@Vevo) July 5, 2018
More info & further work
If you’re interested, the code for my analysis is available here. I also did some of this work as live coding, which you can follow along with on YouTube here.
For future work, I’m planning on looking at which kinds of emoji are more likely to be repeated. My intuition is that gestural emoji (so anything with a hand or face) are more likely to be repeated than other types of emoji–which would definitely add some fuel to the “are emoji words or gestures” debate!
