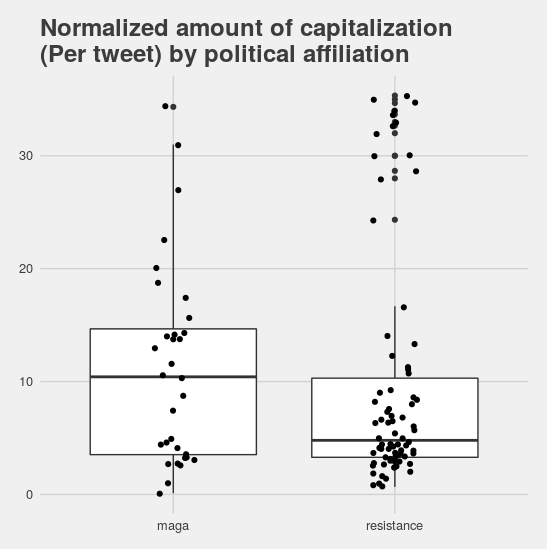
One of the nice things about human language is that no matter what your question about it might be, someone, somewhere has almost certainly already asked the same thing… and probably found at least part of an answer! The downside of this wealth of knowledge is that, even if you restrict yourself to just looking at the Western academic tradition, 1) there’s a lot of it and 2) it’s scattered across a lot of disciplines which can make it very hard to find.
An academic discipline is a field of study but also a social network of scholars with shared norms and vocabulary. While people do do “interdisciplinary” work that draws on more than one discipline, the majority of academic life is structured around working in a single discipline. This is reflected in everything from departments to journals and conferences to how research funding is divided.
As a result, even if you study human language in some capacity yourself it can be very hard to form a good idea of where else people are doing related work if it falls into another discipline you don’t have contact with. You won’t see them at your conferences, you probably won’t cite each other in your papers and even if you are studying the exact same thing you’ll probably use different words to describe it and have different reserach goals. As a result, even many researchers working in language may not know what’s happening in the discipline next door.
For better or worse, though, I’ve always been very curious about disciplinary boundaries and talk and read to a lot of folks and, as a result, have ended up learning a lot about different disciplines. (Note: I don’t know that I’d recommend this to other junior scholars. It made me a bit of a “neither fish nor fowl” when I was on the faculty job market. I did have fun though. 😉 The upside of this is that I’ve had at least three discussions with people where the gist of it was “here are the academic fields that are relevant to your interest” and so I figured it was time to write it up as a blog post to save myself some time in the future.
Disciplines where language is the main focus
These fields study language itself. While people working in these fields may use different tools and have different goals, these are fields where people are likely to say that language is their area of study.
Linguistics
This is the field that studies Language and how it works. Sometimes you’ll hear people talk about “capital L language” to distinguish it from the study of a specific language. Whatever tools or methods or theoretical linguists use, their main object of study is language itself. There a lot of fields within linguistics and they vary a lot, but generally if a field has “linguistics” on the end, they’re going to be focusing on language itself.
For more information about linguistics, check out the Linguistic Society of America or my friend Gretchen’s blog.
Language-specific disciplines (classics, English, literature, foreign language departments etc.)
This is a collection of disciplines that study particular languages and specific instances of language use (like specific documents or pieces of oral literature). These fields generally focus on language teaching or applying frameworks like critical theory to better understand texts. Oh, or they produce new texts themselves. If you ask someone in one of these fields what they study, they’ll probably say the name of the specific language or family of languages they work on.
There are a lot of different fields that fall under this umbrella, so I’d recommend searching for “[whatever language you what to know about ] studies” and taking it from there.
Speech language pathology/Audiology/Speech and hearing
I’m grouping these disciplines together because they generally focus on language in a medical context. The main focus of researchers in this field is studying how the human body produces and receives language input. A lot of the work here focus on identifying and treating instances when these processes break down.
A good place to learn more is the American Speech-Language-Hearing Association.
Computer science (Specifically natural language processing, computational linguistics)
This field (more likely to be called NLP these days) focuses on building and understanding computational systems where language data, usually text, is part of either the input or output. Currently the main focus on the field (in terms of press coverage and $$ at any rate) is in applying machine learning methods to various problems. A lot of work in NLP is focused around particular tasks which generally have an associated dataset and shared metric and where the aim is to outperform other systems on the same problem. NLP does use some methods from other fields of machine learning (like computer vision) but the majority of the work uses techniques specific to, or at least developed for, language data.
To learn more, I’d check out the Association for Computational Linguistics. (Note that “NLP” is also an acronym for a pseudoscienience thing so I’d recommend searching #NLProc or “Natural Language Processing” instead.)
For reference, I would say that currently my main field is in applied NLP, but my background is primarily in linguistics and sprinkling of language-specific studies, especially English and American Sign Language. (Although I’ve taken course work and been a co-author on papers in speech & hearing.)
Disciplines where language is sometimes studied
There are also a lot of related fields where language data is used, or language is used as a tool to study a different object of inquiry.
- Data Science. You would you shocked how much of data science is working with text data (or maybe you’re a data scientist and you wouldn’t be). Pretty much every organization has some sort of text they would like to learn about without having to read it all.
- Computational social science, which uses language data but also frequently other types of data produced by human interaction with computational system. The aim is usually more to model or understand society rather than language use.
- Anthropology, where language data is often used to better understand humans. (As a note, early British anthropology in particular is straight up racist imperial apologism, so be ye warned. There have been massive changes in the field, thankfully.) A lot of language documentation used to happen in anthropology departments, although these days I think it tends to be more linguistics. The linguistic-focused subdisciplines are anthropological linguistics or linguistic anthropology (they’re slightly different).
- Sociology, the study of society. Sociolinguistics is more sociologically-informed linguistics, and in the US historically has been slightly more macro focused.
- Psychology/Cognitive science. Non-physical brain stuff, like the mind and behavior. The linguistic part is psycholinguistics. This is where a lot of the work on language learning goes on.
- Neurology. Physical brain stuff. The linguistic part is neurolinguistics. They tend to do a lot of imaging.
- Education. A lot of the literature on language learning is in education. (Language learning is not to be confused with language acquisition; that’s only for the process by which children naturally acquire a language without formal instruction.)
- Electrical engineering (Signal processing). This is generally the field of folks who are working on telephony and automatic speech recognition. NLP historically hasn’t done as much with voices, that’s been in electrical engineering/signal processing.
- Disability studies. A lot of work on signed languages will be in disability studies departments if they don’t have their own department.
- Historians. While they aren’t primarily studying the changes in linguistic systems, historians interact with older language data a lot and provide context for things like language contact, shift and historical usage.
- Informatics/information science/library science. Information science is broader than linguistics (including non-linguistic information all well) but often dovetails with it, especially in semantics (the study of meaning) and ontologies (a formal representation of categories and their relations).
- Information theory. This field is superficially focused on how digital information is encoded. Usually linguistics draws from it rather than vice-versa because it’s lower level, but if you’ve heard of entropy, compression or source-channel theory those are all from information theory.
- Philosophy. A lot of early linguistics scholars, like Ferdinand de Saussure, would probably have considered themselves primarily philosophers and there was this whole big thing in the early 1900’s. The language-specific branch is philosophy of language.
- Semiotics. This is a field I haven’t interacted with too much (I get the impression that it’s more popular in Europe than the US) but they study “signs”, which as I understand it is any way of referring to a thing in any medium without using the actual thing, which by that definition does include language.
- Design studies. Another field I’m not super familiar with, but my understanding is that it includes studying how users of a designed thing interact with it, which may include how they use or interpret language. Also: good design is so important and I really don’t think designers get enough credit/kudos.







_(8250815324).jpg)