
If your primary dialect is something other than Standardized American English (that sort of from-the-US-but-not-anywhere-in-particular type of English you hear a lot of on the news) you may have noticed that speech recognition software doesn’t generally work very well for you. You can see the sort of thing I’m talking about in this clip:
This clip is a little old, though (2010). Surely voice recognition technology has improved since then, right? I mean, we’ve got more data and more computing power than ever. Surely somebody’s gotten around to making sure that the current generation of voice-recognition software deals equally well with different dialects of English. Especially given that those self-driving cars that everyone’s so excited about are probably going to use voice-based interfaces.
To check, I spent some time on Youtube looking at the accuracy automatic captions for videos of the accent tag challenge, which was developed by Bert Vaux. I picked Youtube automatic captions because they’re done with Google’s Automatic Speech Recognition technology–which is one of the most accurate commercial systems out there right now.
Data: I picked videos with accents from Maine (U.S), Georgia (U.S.), California (U.S), Scotland and New Zealand. I picked these locations because they’re pretty far from each other and also have pretty distinct regional accents. All speakers from the U.S. were (by my best guess) white and all looked to be young-ish. I’m not great at judging age, but I’m pretty confident no one was above fifty or so.
What I did: For each location, I checked the accuracy of the automatic captions on the word-list part of the challenge for five male and five female speakers. So I have data for a total of 50 people across 5 dialect regions. For each word in the word list, I marked it as “correct” if the entire word was correctly captioned on the first try. Anything else was marked wrong. To be fair, the words in the accent tag challenge were specifically chosen because they have a lot of possible variation. On the other hand, they’re single words spoken in isolation, which is pretty much the best case scenario for automatic speech recognition, so I think it balances out.
Ok, now the part you’ve all been waiting for: the results. Which dialects fared better and which worse? Does dialect even matter? First the good news: based on my (admittedly pretty small) sample, the effect of dialect is so weak that you’d have to be really generous to call it reliable. A linear model that estimated number of correct classifications based on total number of words, speaker’s gender and speaker’s dialect area fared only slightly better (p = 0.08) than one that didn’t include dialect area. Which is great! No effect means dialect doesn’t matter, right?
Weellll, not really. Based on a power analysis, I really should have sampled forty people from each dialect, not ten. Unfortunately, while I love y’all and also the search for knowledge, I’m not going to hand-annotate two hundred Youtube videos for a side project. (If you’d like to add data, though, feel free to branch the dataset on Github here. Just make sure to check the URL for the video you’re looking at so we don’t double dip.)
So while I can’t confidently state there is an effect, based on the fact that I’m sort of starting to get one with only a quarter of the amount of data I should be using, I’m actually pretty sure there is one. No one’s enjoying stellar performance (there’s a reason that they tend to be called AutoCraptions in the Deaf community) but some dialect areas are doing better than others. Look at this chart of accuracy by dialect region:
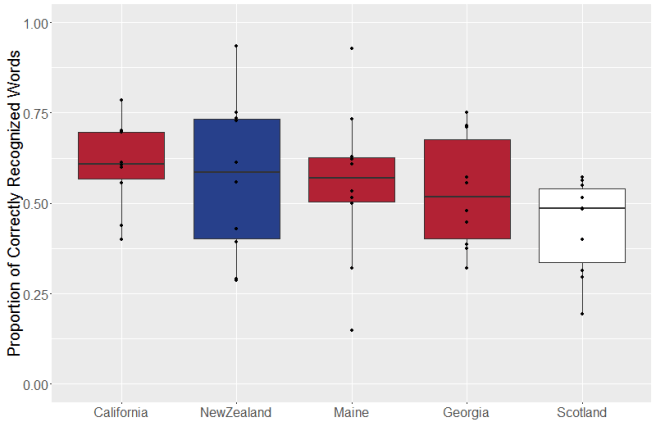
There’s variation, sure, but in general the recognizer seems to be working best on people from California (which just happens to be where Google is headquartered) and worst on Scottish English. The big surprise for me is how well the recognizer works on New Zealand English, especially compared to Scottish English. It’s not a function of country population (NZ = 4.4 million, Scotland = 5.2 million). My guess is that it might be due to sample bias in the training sets, especially if, say, there was some 90’s TV shows in there; there’s a lot of captioned New Zealand English in Hercules, Xena and related spin-offs. There’s also a Google outreach team in New Zealand, but not Scotland, so that might be a factor as well.
So, unfortunately, it looks like the lift skit may still be current. ASR still works better for some dialects than others. And, keep in mind, these are all native English speakers! I didn’t look at non-native English speakers, but I’m willing to bet the system is also letting them down. Which is a shame. It’s a pity that how well voice recognition works for you is still dependent on where you’re from. Maybe in another six years I’ll be able to write a blog post says it isn’t.

This is a great idea! I think I’m going to do something similar as an exercise with my English Dialects students in the spring. I’ll report back, and happily credit you.