
So if you’re a weird internet nerd like me, you might already know that Unicode 9.0 was released today. The deets are here, but they’re fairly boring unless you really care about typography. What’s more interesting to me, as someone who studies visual, spoken and written language, is that there are a whole batch of new emoji. And it’s led to lots of interesting speculation about, for example, what is the most popular new emoji is going to be (tldr: probably the ROFL face. People have a strong preference for using positive face emojis.) This led me to wonder: what obvious lexical gaps are there?
[I]n some cases it is useful to refer to the words that are not part of the vocabulary: the nonexisting words. Instead of referring to nonexisting words, it is common to speak about lexical gaps, since the nonexisting words are indications of “holes” in the lexicon of the language that could be filled.
Janssen, M. 2012. “Lexical Gaps”. The Encyclopedia of Applied Linguistics.
This question is pretty easy to answer about emoji– we can just find out what words people are most likely to use when they’re complaining about not being able to use emoji. There’s even a Twitter bot that collects these kind of tweets. I decided to do something similar, but with a twist. I wanted to know what kinds of emoji people complain about wanting the most.
Boring technical details 💤
- Yesterday, I grabbed 4817 recent tweets that contained both the words “no” and “emoji”. (You can find the R script I used for this on my Github.)
- For each tweet, I took the two words occurring directly in front of the word “emoji” and created a corpus from them using the tm (text mining) package.
- I tidied up the corpus–removing super-common words like “the”, making everything lower-case, and so on. (The technical term is “cleaning“, but I like the sound of tidying better. It sounds like you’re getting comfy with your data, not delousing it.)
- I ranked these words by frequency, or how often then showed up. There were 1888 distinct words, but the vast majority (1280) showed up only once. This is completely normal for word frequency data and is modelled by Zipf’s law.
- I then took all words that occurred more than three times and did a content analysis.
Exciting results! 😄
At the end of my content analysis, I arrived at nine distinct categories. I’ve listed them below, with the most popular four terms from each. One thing I noticed right off is how many of these are emoji that either already exist or are in the Unicode update. To highlight this, I’ve italicized terms in the list below that don’t have an emoji.
- animal: shark, giraffe, butterfly, duck
- color: orange, red, white, green
- face: crying, angry, love, hate
- (facial) feature: mustache, redhead, beard, glasses
- flag: flag, England, Welsh, pride
- food: bacon, avocado, salt, carrot
- gesture: peace, finger, middle, crossed
- object: rifle, gun, drum, spoon
- person: mermaid, pirate, clown, chef
(One note: the rifle is in unicode 9.0, but isn’t an emoji. This has been the topic of some discussion, and is probably why it’s so frequent.)
Based on these categories, where are the lexical gaps? The three categories that have the most different items in them are, in order 1) food, 2) animals and 3) objects. These are also the three categories with the most mentions across all items.
So, given that so many people are talking about emojis for animals, food and objects, why aren’t the bulk of emojis in these categories? We can see why this might be by comparing how many different items get mentioned in each category to how many times each item is mentioned.
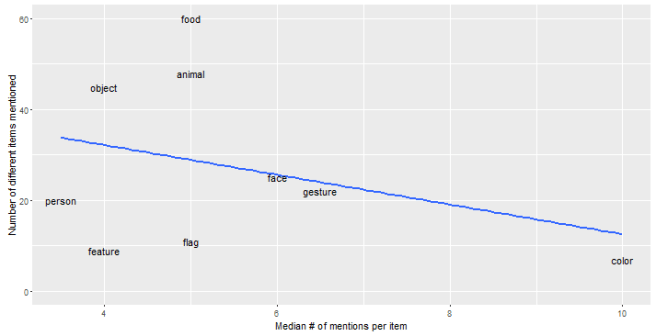
As you can see from the figure above, the most popular categories have a lot of different things in them, but each thing is mentioned relatively rarely. So while there is an impassioned zebra emoji fanbase, it only comes up three times in this dataset. On the other hand, “red” is fairly common but shows up because of discussion of, among other things, flowers, shoes and hair color. Some categories, like flags, fall in a happy medium–lots of discussion and fairly few suggestions for additions.
Based on this teeny data set, I’d say that if the Unicode consortium continues to be in charge of putting emoji standardization it’ll have its hands full for quite some time to come. There’s a lot of room for growth, and most of it is in food, animals and objects, which all have a lot of possible items, rather than gestures or facial expressions, which have much fewer.
