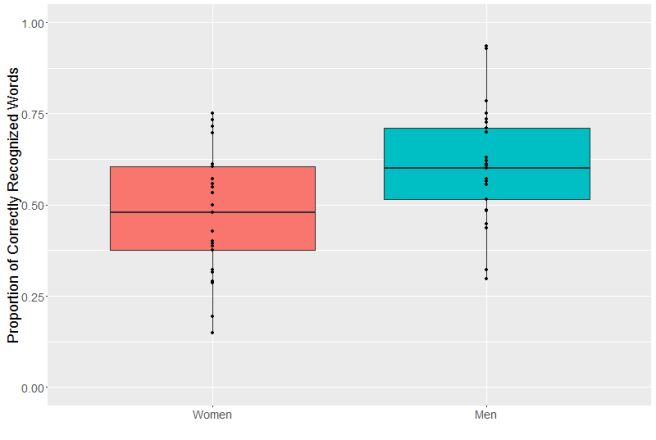
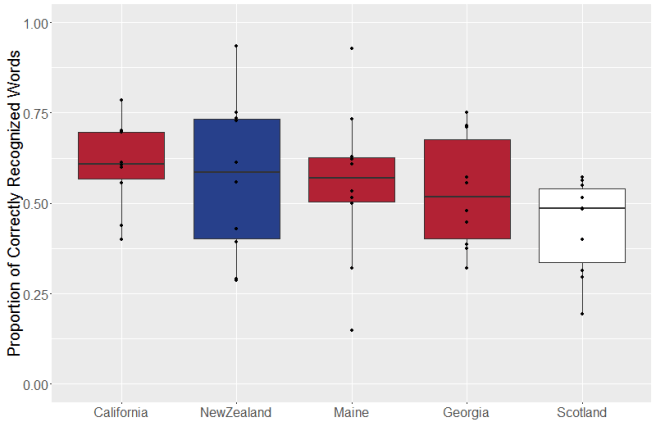
So after my last blog post went up, a couple people wondered if the difference in classification error rates between men and women might be due to pitch, since men tend to have lower voices. I had no idea, so, being experimentally inclined, I decided to find out.
First, I found the longest list of words that I could from the accent tag. Pretty much every video I looked used a subset of these words.
Aunt, Roof, Route, Wash, Oil, Theater, Iron, Salmon, Caramel, Fire, Water, Sure, Data, Ruin, Crayon, New Orleans, Pecan, Marriage, Both, Again, Probably, Spitting Image, Alabama, Guarantee, Lawyer, Coupon, Mayonnaise, Ask, Potato, Three, Syrup, Cool Whip, Pajamas, Caught, Catch, Naturally, Car, Aluminium, Envelope, Arizonia, Waffle, Auto, Tomato, Figure, Eleven, Atlantic, Sandwich, Attitude, Officer, Avacodo, Saw, Bandana, Oregon, Twenty, Halloween, Quarter, Muslim, Florida, Wagon
Then I recorded myself reading them at a natural pace, with list intonation. In order to better match the speakers in the other Youtube videos, I didn’t go into the lab and break out the good microphones; I just grabbed my gaming headset and used that mic. Then, I used Praat (a free, open source software package for phonetics) to shift the pitch of the whole file up and down 60 Hertz in 20 Hertz intervals. That left me with seven total sound files: the original one, three files that were 20, 40 and 60 Hertz higher and finally three files that were 20, 40 and 60 Hertz lower. You can listen to all the files individually here.
The original recording had a mean of 192 Hz and a median of 183, which means that my voice is slightly lower pitched than average for an American English speakering women. For reference, Pepiot 2014 found a mean pitch of 210 Hz for female American English speakers. The same papers also lists a mean pitch of 119 Hz for male American English speakers. This means that my lowest pitch manipulation (mean of 132) is still higher than the average American English speaking male. I didn’t want to go too much lower with my pitch manipulations, though, because the sound files were starting to sound artifact-y and robotic.
Why did I do things this way?
- Only using one recording. This lets me control 100% for demographic information. I’m the same person, with the same language background, saying the same words in the same way. If I’d picked a bunch of speakers with different pitches, they’d also have different language backgrounds and voices. Plus I’m not getting effects from using different microphones.
- Manipulating pitch both up and down. This was for two reasons. First, it means that the original recording isn’t the end-point for the pitch continuum. Second, it means that we can pick apart whether accuracy is a function of pitch or just the file having been manipulated.
Results:
You can check out how well the auto-captions did yourself by checking out this video. Make sure to hit the CC button in the lower left-hand corner.
The first thing I noticed was that I had really, really good results with the auto captions. Waaayyyy better than any of the other videos I looked at. There were nine errors across 434 tokens, for a total error rate of only 2%, which I’d call pretty much at ceiling. There was maaayybe a slight effect of the pitch manipulation, with higher pitches having slightly higher error rates, as you can see:
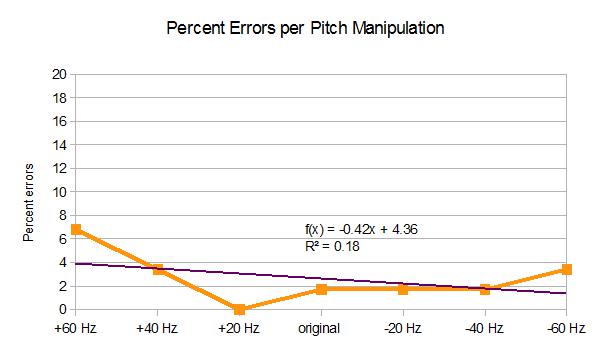
BUT there’s also sort of a u-shaped curve, which suggests to me that the recognizer is doing worse with the files that have been messed with the most. (Although, weirdly, only the file that had had its pitched shifted up by 20 Hz had no errors.) I’m going to go ahead and say that I’m not convinced that pitch is a determining factor
So why were these captions so much better than the ones I looked at in my last post? It could just be that I was talking very slowly and clearly. To check that out, I looked at autocaptions for the most recent video posted by someone who’s fairly similar to me in terms of social and vocal characteristics: a white woman who speaks standardized American English with Southern features. Ideally I’d match for socioeconomic class, education and rural/urban background as well, but those are harder to get information about.
I chose Bunny Meyer, who posts videos as Grav3yardgirl. In this video her speech style is fast and conversational, as you can hear for yourself:
To make sure I had roughly the same amount of data as I had before, I checked the captions for the first 445 words, which was about two minutes worth of video (you can check my work here). There was an overall error rate of approximately 8%, if you count skipped words as errors. Which, considering that recognizing words in fast/connected speech is generally more error-prone, is pretty good. It’s definitely better than in the videos I analyzed for my last post. It’s also a fairly small difference from my careful speech: definitely less than the 13% difference I found for gender.
So it looks like neither the speed of speech nor the pitch are strongly affecting recognition rate (at least for videos captioned recently). There are a couple other things that I think may be going on here that I’m going to keep poking at:
- ASR has got better over time. It’s totally possible that more women just did the accent tag challenge earlier, and thus had higher error rates because the speech recognition system was older and less good. I’m going to go back and tag my dataset for date, though, and see if that shakes out some of the gender differences.
- Being louder may be important, especially in less clear recordings. I used a head-mounted microphone in a quiet room to make my recordings, and I’m assuming that Bunny uses professional recording equipment. If you’re recording outside or with a device microphone, though, there going to be a lot more noise. If your voice is louder, and men’s voices tend to be, it should be easier to understand in noise. My intuition is that, since there are gender differences in how loud people talk, some of the error may be due to intensity differences in noisy recordings. Although an earlier study found no difference in speech recognition rates for men and women in airplane cockpits, which are very noisy, so who knows? Testing that out will have to wait for another day, though.