
You may already be familiar with the phenomena I’m going to be talking about today: when someone punctuates some text with the clap emoji. It’s a pretty transparent gestural scoring and (for me) immediately brings to mind the way my mom would clap with every word when she was particularly exasperated with my sibling and I (it was usually along with speech like “let’s go, let’s go, let’s go” or “get up now”). It looks like so:
This innovation, which started on Black Twitter is really interesting to me because it ties in with my earlier work on emoji ordering. I want to know where emojis go, particularly in relation to other words. Especially since people have since extended this usage to other emoji, like the US Flag:
Logically, there are several different ways you can intersperse clap emojis with text:
- Claps 👏 are 👏 used 👏 between 👏 every 👏 word.
- 👏 Claps 👏 are 👏 used 👏 around 👏 every 👏 word. 👏
- 👏 Claps 👏 are 👏 used 👏 before 👏 every 👏 word.
- Claps 👏 are 👏 used 👏 after 👏 every 👏 word. 👏
- Claps 👏 are used 👏 between phrases 👏 not words
I want to know which of these best describes what people actually do. I’m not aiming to write an internet style guide, but I am hoping to characterize this phenomena in a general way: this is how most people who do this do it, and if you want to use this style in a natural way, you should probably do it the same way.
Data
I used Fireant to grab 10,000 tweets from the Twitter streaming API which had the clap emoji in them at least once. (Twitter doesn’t let you search for a certain number of matches of the same string. If you search for “blob” and “blob blob” you’ll get the same set of results.)
Analysis
From that set of 10,000 tweets, I took only the tweets that had a clap emoji followed by a word followed by another clap emoji and threw out any repeats. That left me with 260 tweets. (This may seem pretty small compared to my starting dataset, but there were a lot of retweets in there, and I didn’t want to count anything twice.) Then I removed @usernames, since those show up in the beginning of any tweet that’s a reply to someone, and URL’s, which I don’t really think of as “words”. Finally, I looked at each word in a tweet and marked whether it was a clap or not. You can see the results of that here:
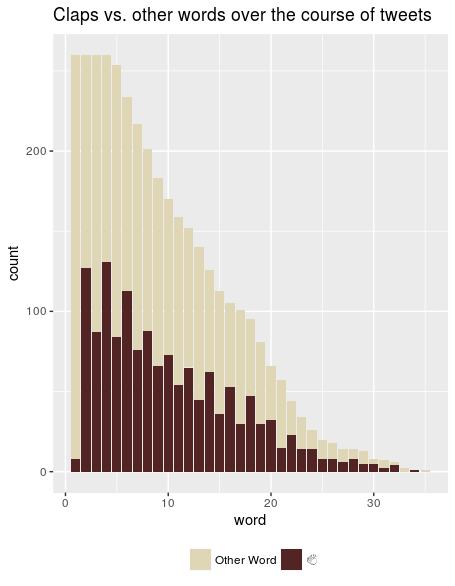
The “word” axis represents which word in the tweet we’re looking at: the first, second, third, etc. The red portion of the bar are the words that are the clap emoji. The yellow portion is the words that aren’t. (BTW, big shoutout to Hadley Wickham’s emo(ji) package for letting me include emoji in plots!)
From this we can see a clear pattern: almost no one starts a tweet with an emoji, but most people follow the first word with an emoji. The up-down-up-down pattern means that people are alternating the clap emoji with one word. So if we look back at our hypotheses about how emoji are used, we can see right off the bat that three of them are wrong:
- Claps 👏 are 👏 used 👏 between 👏 every 👏 word.
-
👏 Claps 👏 are 👏 used 👏 around 👏 every 👏 word. 👏 👏 Claps 👏 are 👏 used 👏 before 👏 every 👏 word.- Claps 👏 are 👏 used 👏 after 👏 every 👏 word. 👏
Claps 👏 are used 👏 between phrases 👏 not words
We can pick between the two remaining hypotheses by looking at whether people are ending thier tweets with a clap emoji. As it turns out, the answer is “yes”, more often than not.

If they’re using this clapping-between-words pattern (sometimes called the “ratchet clap“) people are statistically more likely to end their tweet with a clap emoji than with a different word or non-clap emoji. This means the most common pattern is to use 👏 a 👏 clap 👏 after 👏 every 👏 word, 👏 including 👏 the 👏 last. 👏
This makes intuitive sense to me. This pattern is mimicking someone is clapping on every word. Since we can’t put emoji on top of words to indicate that they’re happening at the same time, putting them after makes good intuitive sense. In some sense, each emoji is “attached” to the word that comes before it in a similar way to how “quickly” is “attached” to “run” in the phrase “run quickly”. It makes less sense to put emoji between words, becuase then you end up with less claps than words, which doesn’t line up well with the way this is done in speech.
The “clap after every word” pattern is also what this website that automatically puts claps in your tweets does, so I’m pretty positive this is a good characterization of community norms.
So there you have it! If you’re going to put clap emoji in your tweets, you should probably do 👏 it 👏 like 👏 this. 👏 It’s not wrong if you don’t, but it does look kind of weird.








.JPG)



.jpg)

{kind=link}
{kind=link}