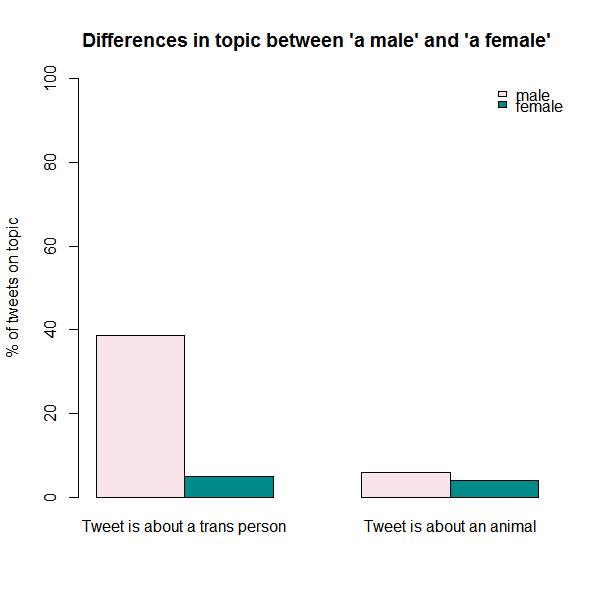This blog post is more of a quick record of my thoughts than a full in-depth analysis, because when I saw this I immediately wanted to start writing about it. Basically, TikTok is a social media app for short form video (RIP Vine, forever in our hearts) and one of the most popular genres of content is short dances; you may already be familiar with the concept.
HOWEVER, what’s particularly intriguing to me is this sort of video here, where someone creates a tutorial for a specific dance and includes an emoji-based dance notation:
Example of a dance with an emoji notation system by
Back in grad school, when I was studying signed languages, I probably spent more time than I should have reading about writing systems for signed languages and also dance notations. To roughly sum up an entire field of study: representing movements of the human body in time and space using a writing system, or even a more specialized notation, is extremely difficult. There are a LOT of other notations out there, and you probably haven’t run into them for a reason: they’re complex, hard to learn, necessarily miss nuances and are a bit redundant given that the vast majority of dance is learned through watching & copying movement. Probably the most well-known type of dance notation is for ballroom dance where the footwork patterns are represented on the floor using images of footsteps, like so:
I think part of the reason that this notation in particular tends to work well is that it’s completely iconic: the image of a shoe print is where your shoe print should go. It also captures a large part of the relevant information; the upper body position can be inferred from the position of the feet (and in many cases will more or less remain the same throughout).
I think that’s true to some degree of these emoji notations as well. The fact that they work at all may be arising in part due to the constraints of the TikTok dance genre. In most TikTok dances, the dancer faces in a single direction for the dance, there is minimal movement around the space and the feet move minimally if at all. The performance format itself helps as well: the videos are short and easy to repeat, and you can still see the movements being preformed in full with the notation being used as a shorthand.
And it’s clear that this use of style of notation isn’t idiosyncratic; this compilation has a variety of tutorials from different creators that use variations on the same style of notation.
A selection of tiktok dance tutorials, some of which include emoji notation
Some of the types of ways emoji are used here are similar to the ways that things like Stokoe notation are, to indicate handshape and movement (although not location). A few other types of ways that emoji are used that stick out:
Articulator (hands with handshape, peach emoji for the hips)
Manner of articulation/movement (“explosive”, a specific number of repetitions, direction of movement using arrows)
Iconic representation of a movement using an object (helicopter = hands make the motion of helicopter blades, mermaid = bodywaves, as if a mermaid swimming)
Iconic representation of a shape to be traced (a house emoji = tracing a house shape with the hands, heart = trace a heart shape)
(Not emoji) Written shorthand for a (presumably) already known dance, for example “WOAH” for the woah
To sum up: I think this is a cool idea, it’s an interesting new type of dance notation that is clearly useful to a specific artistic community. It’s also another really good piece of evidence in the bucket of “emoji are gestures”: these are clearly not a linguistic system and are used in a variety of ways by different users that don’t seem entirely systematic.
Buuuut there’s also the way that the emojis are groups into phrases for a specific set of related motions, which smells like some sort of shallow parsing even if it’s not a full consistency structure, and I’d say that’s definitely linguistic-ish. I think I’d need to spend more time on analysis to have any more firmly held opinion than that.
One of the nice things about human language is that no matter what your question about it might be, someone, somewhere has almost certainly already asked the same thing… and probably found at least part of an answer! The downside of this wealth of knowledge is that, even if you restrict yourself to just looking at the Western academic tradition, 1) there’s a lot of it and 2) it’s scattered across a lot of disciplines which can make it very hard to find.
An academic discipline is a field of study but also a social network of scholars with shared norms and vocabulary. While people do do “interdisciplinary” work that draws on more than one discipline, the majority of academic life is structured around working in a single discipline. This is reflected in everything from departments to journals and conferences to how research funding is divided.
As a result, even if you study human language in some capacity yourself it can be very hard to form a good idea of where else people are doing related work if it falls into another discipline you don’t have contact with. You won’t see them at your conferences, you probably won’t cite each other in your papers and even if you are studying the exact same thing you’ll probably use different words to describe it and have different reserach goals. As a result, even many researchers working in language may not know what’s happening in the discipline next door.
For better or worse, though, I’ve always been very curious about disciplinary boundaries and talk and read to a lot of folks and, as a result, have ended up learning a lot about different disciplines. (Note: I don’t know that I’d recommend this to other junior scholars. It made me a bit of a “neither fish nor fowl” when I was on the faculty job market. I did have fun though. 😉 The upside of this is that I’ve had at least three discussions with people where the gist of it was “here are the academic fields that are relevant to your interest” and so I figured it was time to write it up as a blog post to save myself some time in the future.
Disciplines where language is the main focus
These fields study language itself. While people working in these fields may use different tools and have different goals, these are fields where people are likely to say that language is their area of study.
Linguistics
This is the field that studies Language and how it works. Sometimes you’ll hear people talk about “capital L language” to distinguish it from the study of a specific language. Whatever tools or methods or theoretical linguists use, their main object of study is language itself. There a lot of fields within linguistics and they vary a lot, but generally if a field has “linguistics” on the end, they’re going to be focusing on language itself.
Language-specific disciplines (classics, English, literature, foreign language departments etc.)
This is a collection of disciplines that study particular languages and specific instances of language use (like specific documents or pieces of oral literature). These fields generally focus on language teaching or applying frameworks like critical theory to better understand texts. Oh, or they produce new texts themselves. If you ask someone in one of these fields what they study, they’ll probably say the name of the specific language or family of languages they work on.
There are a lot of different fields that fall under this umbrella, so I’d recommend searching for “[whatever language you what to know about ] studies” and taking it from there.
Speech language pathology/Audiology/Speech and hearing
I’m grouping these disciplines together because they generally focus on language in a medical context. The main focus of researchers in this field is studying how the human body produces and receives language input. A lot of the work here focus on identifying and treating instances when these processes break down.
Computer science (Specifically natural language processing, computational linguistics)
This field (more likely to be called NLP these days) focuses on building and understanding computational systems where language data, usually text, is part of either the input or output. Currently the main focus on the field (in terms of press coverage and $$ at any rate) is in applying machine learning methods to various problems. A lot of work in NLP is focused around particular tasks which generally have an associated dataset and shared metric and where the aim is to outperform other systems on the same problem. NLP does use some methods from other fields of machine learning (like computer vision) but the majority of the work uses techniques specific to, or at least developed for, language data.
To learn more, I’d check out the Association for Computational Linguistics. (Note that “NLP” is also an acronym for a pseudoscienience thing so I’d recommend searching #NLProc or “Natural Language Processing” instead.)
For reference, I would say that currently my main field is in applied NLP, but my background is primarily in linguistics and sprinkling of language-specific studies, especially English and American Sign Language. (Although I’ve taken course work and been a co-author on papers in speech & hearing.)
Disciplines where language is sometimes studied
There are also a lot of related fields where language data is used, or language is used as a tool to study a different object of inquiry.
Data Science. You would you shocked how much of data science is working with text data (or maybe you’re a data scientist and you wouldn’t be). Pretty much every organization has some sort of text they would like to learn about without having to read it all.
Computational social science, which uses language data but also frequently other types of data produced by human interaction with computational system. The aim is usually more to model or understand society rather than language use.
Anthropology, where language data is often used to better understand humans. (As a note, early British anthropology in particular is straight up racist imperial apologism, so be ye warned. There have been massive changes in the field, thankfully.) A lot of language documentation used to happen in anthropology departments, although these days I think it tends to be more linguistics. The linguistic-focused subdisciplines are anthropological linguistics or linguistic anthropology (they’re slightly different).
Sociology, the study of society. Sociolinguistics is more sociologically-informed linguistics, and in the US historically has been slightly more macro focused.
Psychology/Cognitive science. Non-physical brain stuff, like the mind and behavior. The linguistic part is psycholinguistics. This is where a lot of the work on language learning goes on.
Neurology. Physical brain stuff. The linguistic part is neurolinguistics. They tend to do a lot of imaging.
Education. A lot of the literature on language learning is in education. (Language learning is not to be confused with language acquisition; that’s only for the process by which children naturally acquire a language without formal instruction.)
Electrical engineering (Signal processing). This is generally the field of folks who are working on telephony and automatic speech recognition. NLP historically hasn’t done as much with voices, that’s been in electrical engineering/signal processing.
Disability studies. A lot of work on signed languages will be in disability studies departments if they don’t have their own department.
Historians. While they aren’t primarily studying the changes in linguistic systems, historians interact with older language data a lot and provide context for things like language contact, shift and historical usage.
Informatics/information science/library science. Information science is broader than linguistics (including non-linguistic information all well) but often dovetails with it, especially in semantics (the study of meaning) and ontologies (a formal representation of categories and their relations).
Information theory. This field is superficially focused on how digital information is encoded. Usually linguistics draws from it rather than vice-versa because it’s lower level, but if you’ve heard of entropy, compression or source-channel theory those are all from information theory.
Philosophy. A lot of early linguistics scholars, like Ferdinand de Saussure, would probably have considered themselves primarily philosophers and there was this whole big thing in the early 1900’s. The language-specific branch is philosophy of language.
Semiotics. This is a field I haven’t interacted with too much (I get the impression that it’s more popular in Europe than the US) but they study “signs”, which as I understand it is any way of referring to a thing in any medium without using the actual thing, which by that definition does include language.
Design studies. Another field I’m not super familiar with, but my understanding is that it includes studying how users of a designed thing interact with it, which may include how they use or interpret language. Also: good design is so important and I really don’t think designers get enough credit/kudos.
Let’s start with the good news: research using social media data has revolutionized social science research. It’s let us ask bigger question more quickly, helped us overcome some of the key drawbacks of behavioral experimental work and ask new kinds of questions.
More data faster
I can’t overstate how revolutionary the easy availability of social media data has been, especially in linguistics. It has increased both the rate and scale of data collection by orders of magnitude. Compare the time it took to compare the Dictionary of American Regional English (DARE) to the Wordmapper app below. The results are more or less the same, maps of where in the US folks use different words (in this example, “cellar”). But what once took the entire careers of multiple researchers can now be done in a few months, and with far higher resolution.
One of the constant struggles in experimental work is the fact that the mere fact of being observed changes behavior. This is known as the Hawthorne Effect in psychology or the Observer’s Paradox in sociolinguistics. As a result, even the most well-designed experiment is limited by the fact that the participants know that they are completing an experiment.
Social media data, however, doesn’t have this limitation. Since most social media research projects are conducted on public data without interacting directly with participants, they are not generally considered human subjects research. When you post something on a public social media account, you don’t have a reasonable expectation of privacy. In other words, you know that just anyone could come along and read it, and that includes researchers. As a result it is not generally necessary to collect informed consent for social media projects. (Informed consent is when you are told exactly what’s going to happen during an experiment you’re participating, and you agree to participate in it.) This means that the vast majority of folks who are participating in a social media study don’t actually know that they’re part of a study.
The benefit of this is that it allows researchers to get around three common confounds that plague social science research:
Bradley effect: People tend to tell researchers what they think they want to hear
Response bias: The sample of people willing to do an experiment/survey differ in a meaningful way from the population as a whole
Observer’s paradox/Hawthorne effect: People change their behavior when they know they’re being observed
While this is a boon to researchers, the lack of informed consent does introduce other other problems, which we’ll talk about later.
What you can’t do with social media data
Of course, all the benefits of social media come at a cost. There are several key drawbacks and limitations of social media research:
You can’t be sure who your participants are.
There’s inherent sampling bias.
You can’t violate the developer’s agreements.
You’re not sure who you’re studying…
Because you don’t meet with the people whose data is included in your study, you don’t know for sure what sorts of demographic categories they belong to, whether they are who they’re claiming to be or even if they’re human at all. You have to deal with both bots, accounts where content is produced and distributed automatically by a computer and sock puppets, where one person pretends to be another person. Sock puppets in particular can be very difficult to spot and may skew your results in unpredictable ways.
…but you can be sure your sample is biased.
Social media users aren’t randomly drawn from the world’s population as a whole. Social media users tend to be WEIRD: from wealthy, educated, industrialized, rich and democratic societies. This group is already over-represented in social science and psychology research studies, which may be subtly skewing our models of human behavior.
In addition, different social media platforms have different user bases. For example, Instagram and Snapchat tend to have younger users, Pinterest has more women (especially compared to Reddit, which skews male) and LinkedIn users tend to be highly educated and upper middle class. And that doesn’t even get to social network effects: you’re more likely to be on the same platform your friends are on, and since social networks tend to be homophilous, you can end up with pockets of very socially homogeneous folks. So, even if you manage to sample randomly from a social media platform, your sample is likely to differ from one taken from the population as a whole.
You need to abide by the developer’s agreements for whatever platform you’re using data from.
This is mainly an issue if you’re using API (application programmatic interface) to fetch data from a service. Developer’s agreements vary between platforms, but most limit the amount of data you can fetch and store, and how and if you can share it with other researchers. For example, if you’re sharing Twitter data you can only share 50,000 tweets at a time and even then only if you have to have people download a file by clicking on it. If you share any more than that, you should just share the ID’s of the tweets rather than the full tweets. (Document the Now’s Hydrator can help you fetch the tweets associated with a set of IDs.)
What you shouldn’t do with social media data
Finally, there are ethical restrictions on what we should do with social media data. As researchers, we need to 1) respect the wishes of users and 2) safeguard their best interests, especially given that we don’t (currently) generally get informed consent from the folks whose data we’re collecting.
Respecting users’ wishes
At least in the US, ethical human subjects research is led by three guiding principles set forth in the Belmont report. If you’re unfamiliar with the report, it was written in the aftermath of the Tuskegee Valley experiments. These were a series of medical experiments on African Americans men who had contracted syphilis conducted from the 1930’s to 1970’s. During the study, researchers withheld the cure (and even information that it existed) from the participants. The study directly resulted in the preventable deaths of 128 men and many health problems for study participants, their wives and children. It was a clear ethical violation of the human rights of participants and the moral stain of it continues to shape how we conduct human subjects research in the US.
The three principles of ethical human subjects research are:
Respect for Persons: People should be treated as autonomous individuals and persons with diminished autonomy (like children or prisoners) are entitled to protection.
Beneficence: 1) Do not harm and 2) maximize possible benefits and minimize possible harms.
Justice: Both the risks and benefits of research should be distributed equally.
Social media research might not technically fall under the heading of human subjects research, since we aren’t intervening with our participants. However, I still believe that it’s important that researchers following these general guides when designing and distributing experiments.
One thing we can do is respect their wishes of the communities we study. Fortunately, we have some evidence of what those wishes are. Feisler and Proferes (2018) surveyed 368 Twitter users on their perception of a variety of research behaviors.
Fiesler, C., & Proferes, N. (2018). “Participant” Perceptions of Twitter Research Ethics. Social Media+ Society, 4(1), 2056305118763366. Table 4.
In general, Twitter users are more OK with research with the following characteristics:
Large datasets
Analyzed automatically
Social media users informed about research
If tweets are quoted, they are anonymized. (Note that if you include the exact text, it’s possible to reverse search the quoted tweet and de-anonymize it. I recommend changing at least 20% of the content words in a tweet to synonyms to get around this and double-checking by trying to de-anonymize it yourself.)
These characteristics, however, are not as acceptable to Twitter users:
Small datasets
Analysis done by hand (presumably including analysis by Mechanical Turk workers)
Tweets from protected accounts or deleted tweets analyzed (which is also against the developer’s agreement, so you shouldn’t be doing this anyway)
Quoting with citation (very different from academic norms!)
In general, I think these suggest general best practices for researchers working with Twitter data.
Stick to larger datasets
Try to automate wherever possible
Follow the developer’s agreement
Take anonymity seriously.
There is one thing I disagree with, however: I don’t think we should contact everyone who’s tweets we use in our research.
Should we contact people whose tweets we use in our studies? My gut instinct on this one is “no”. If you’re collecting a large amount of data, you probably shouldn’t reach out to everyone in the data.
For users who don’t have open DM’s, the only way to contact them is to publicly mention them using @username. The problem with this is that it partly de-anonymizes your data. If you then choose to share your data, having publicly shared a list of whose data was included in the dataset it makes it much easier to de-anonymize. Instead of trying to figure out whose tweets were included when looking at all of Twitter, an adversary only has to figure out which of the users on the list you’ve given them is connected to which record.
Another aspect of ethical research is trying to ensure that your research or research data doesn’t have potentially unethical applications. The elephant in the room here, of course, is the data Cambridge Analytica collected from Facebook users. Researchers at Cambridge, collecting data for a research project, got lots of people’s permission to access their Facebook data. While that wasn’t a problem, they collected and saved Facebook data from other folks as well, who hadn’t opted in. In the end, only a half of a half of a percent of the folks whose data was in the final dataset actually agreed to be included in it. To make matters worse, this data was used by a commercial company founded by one of the researchers to (possibly) influence elections in the US and UK. Here’s a New York Times article that goes into much more detail. This has understandably lead to increased scrutiny of how social media research data is collected and used.
I’m not bringing this up to call out Facebook in particular, but to explain why it’s important to consider how research data might be used long-term. How and where will it be stored? For how long? Who will have access to it? In short, if you’re a researcher, how can you ensure that data you collected won’t end up somehow hurting the people you collected it from?
As an example of how important these questions are, consider this OK Cupid “research” dataset. It was collected without consent and shared publicly without anonymization. It included many personal details that were only intended to be shared with other users of the site, including explicit statements of sexual orientation. In addition to being an unforgivable breach of privacy, this directly endangered users whose data was collected: information on sexual orientation was shared for people living in countries where homosexuality is a crime that carries a death penalty or sentence of life in prison. I have a lot of other issues with this “study” as well, but the fact that it directly endangered research subjects who had no chance to opt out is by far the most egregious ethical breach.
If you are collecting social media data for research purposes, it is your ethical responsibility to safeguard the well-being of the people whose data you’re using.
I bring up these cautionary tales not to scare you off of social media research but to really impress the gravity of the responsibility you carry as a social media researcher. Social media data has the potential to dramatically improve our understanding of the world. A lot of my own work has relied heavily on it! But it’s important that we, as researchers, take our moral duty to make sure that we don’t end up doing more harm than good very seriously.
Something I’ve been thinking about a lot lately is how much information we really convey with emoji. I was recently at the 1st International Workshop on Emoji Understanding and Applications in Social Media and one theme that stood out to me from the papers was that emoji tend to be used more to communicate social meaning (things like tone and when a conversation is over) than semantics (content stuff like “this is a dog” or “an icecream truck”).
I’ve been itching to apply an information theoretic approach to emoji use for a while, and this seemed like the perfect opportunity. Information theory is the study of storing, transmitting and, most importantly for this project, quantifying information. In other words, using an information theoretic approach we can actually look at two input texts and figure out which one has more information in it. And that’s just what we’re going to do: we’re going to use a measure called “entropy” to directly compare the amount of information in text and emoji.
What’s entropy?
Shannon entropy is a measure of how much information there is in a sequence. Higher entropy means that there’s more uncertainty about what comes next, while lower entropy means there’s less uncertainty. (Mathematically, entropy is always less than or the same as log2(n), where n is the total number of unique characters. You can learn more about calculating entropy and play around with an interactive calculator here if you’re curious.)
So if you have a string of text that’s just one character repeated over and over (like this: 💀💀💀💀💀) you don’t need a lot of extra information to know what the next character will be: it will always be the same thing. So the string “💀💀💀💀💀” has a very low entropy. In this case it’s actually 0, which means that if you’re going through the string and predicting what comes next, you’re always going to be able to guess what comes next becuase it’s always the same thing. On the other hand, if you have a string that’s made up of four different characters, all of which are equally probable (like this:♢♡♧♤♡♧♤♢), then you’ll have an entropy of 2.
TL;DR: The higher the entropy of a string the more information is in it.
Experiment
Hypothesis
We do have some theoretical maximums for the entropy text and emoji. For text, if the text string is just randomly drawn from the 128 ASCII characters (which isn’t how language works, but this is just an approximation) our entropy would be 7. On the other hand, for emoji, if people are just randomly using any emoji they like from the set of emoji as of June 2017, then we’d expect to see an entropy of around 11.
So if people are just using letters or emoji randomly, then text should have lower entropy than emoji. However, I don’t think that’s what’s happening. My hypothesis, based on the amount of repetition in emoji, was that emoji should have lower entropy, i.e. less information, than text.
Data
To get emoji and text spans for our experiment I used four different datasets: three from Twitter and one from YouTube.
I used multiple datasets for a couple reasons. First, becuase I wanted a really large dataset of tweets with emoji, and since only between 0.9% and 0.5% of tweets from each Twitter dataset actually contained emoji I needed to case a wide net. And, second, because I’m growing increasingly concerned about genre effects in NLP research. (Like, a lot of our research is on Twitter data. Which is fine, but I’m worried that we’re narrowing the potential applications of our research becuase of it.) It’s the second reason that led me to include YouTube data. I used Twitter data for my initial exploration and then used the YouTube data to validate my findings.
For each dataset, I grabbed all adjacent emoji from a tweet and stored them separately. So this tweet:
Love going to ballgames! ⚾🌭 Going home to work in my garden now, tho 🌸🌸🌸🌸
Has two spans in it:
Span 1: ⚾🌭
Span 2: 🌸🌸🌸🌸
All told, I ended up with 13,825 tweets with emoji and 18,717 emoji spans of which only 4,713 were longer than one emoji. (I ignored all the emoji spans of length one, since they’ll always have an entropy of 0 and aren’t that interesting to me.) For the YouTube comments, I ended up with 88,629 comments with emoji, 115,707 emoji spans and 47,138 spans with a length greater than one.
In order to look at text as parallel as possible to my emoji spans, I grabbed tweets & YouTube comments without emoji. For each genre, I took a number of texts equal to the number of spans of length > 1 and then calculated the character-level entropy for the emoji spans and the texts.
Analysis
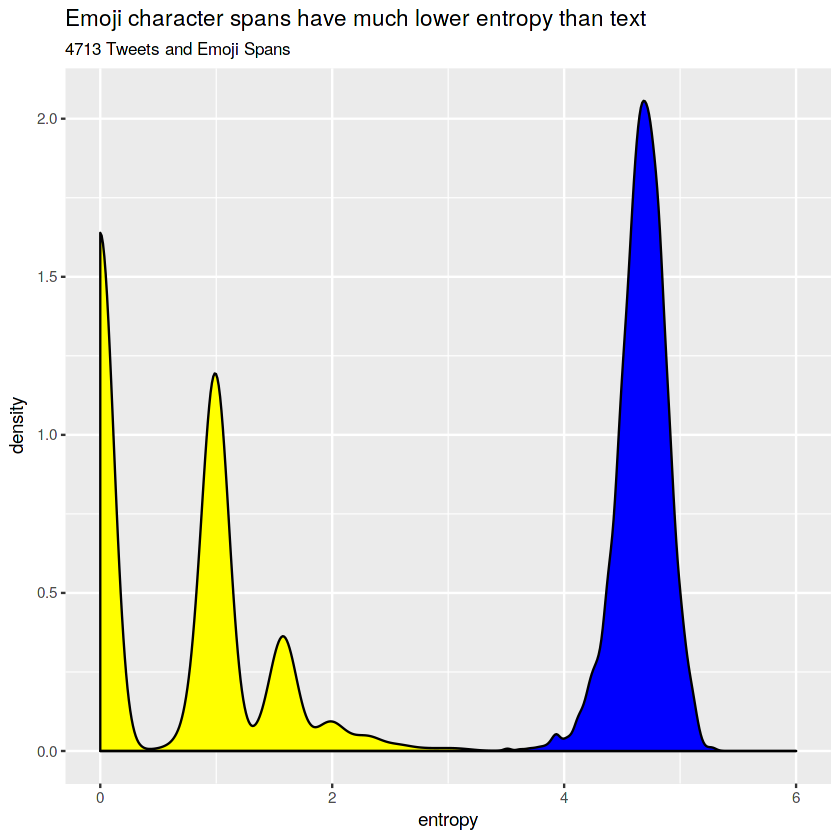
First, let’s look at Tweets. Here’s the density (it’s like a smooth histogram, where the area under the curve is always equal to 1 for each group) of the entropy of an equivalent number of emoji spans and tweets.
Text has a much high character-level entropy than emoji. For text, the mean and median entropy are both around 5. For emoji, there is a multimodal distribution, with the median entropy being 0 and also clusters around 1 and 1.5.
It looks like my hypothesis was right! At least in tweets, text has much more information than emoji. In fact, the most common entropy for an emoji span is 0: which means that most emoji spans with a length greater than one are just repititons of the same emoji over and over again.
But is this just true on Twitter, or does it extend to YouTube comments as well?
The pattern for emoji & text in YouTube comments is very similar to that for Tweets. The biggest difference is that it looks like there’s less information in YouTube Comments that are text-based; they have a mean and median entropy closer to 4 than 5.
The YouTube data, which we have almost ten times more of, corroborates the earlier finding: emoji spans are less informative, and more repetitive, than text.
Which emoji were repeated the most/least often?
Just in case you were wondering, the emoji most likely to be repeated was the skull emoji, 💀. It’s generally used to convey strong negative emotion, especially embarrassment, awkwardness or speechlessness, similar to “ded“.
OMFFFFFFFFFG……….how you gonna put me on blast like that @Oreo!!!!
If you’re interested, the code for my analysis is available here. I also did some of this work as live coding, which you can follow along with on YouTube here.
For future work, I’m planning on looking at which kinds of emoji are more likely to be repeated. My intuition is that gestural emoji (so anything with a hand or face) are more likely to be repeated than other types of emoji–which would definitely add some fuel to the “are emoji words or gestures” debate!
Those of you who know me may know that I’m a big fan of emoji. I’m also a big fan of linguistics and NLP, so, naturally, I’m very curious about the linguistic roles of emoji. Since I figured some of you might also be curious, I’ve pulled together a discussion of some of the very serious scholarly research on emoji. In particular, I’m going to talk about five recent papers that explore the exact linguistic nature of these symbols: what are they and how do we use them?
Emoji are more than just cute pictures! They play a set of very specific linguistic roles.
Dürscheid & Siever, 2017:
This paper makes one overarching point: emoji are not words. They cannot be unambiguously interpreted without supporting text and they do not have clear syntactic relationships to one another. Rather, the authors consider emoji to be specialized characters, and place them within Gallmann’s 1985 hierarchy of graphical signs. The authors show that emoji can play a range of roles within the Gallmann’s functional classification.
Allography: using emoji to replace specific characters (for example: the word “emoji” written as “em😝ji”)
Ideograms: using emoji to replace a specific word (example: “I’m travelling by 🚘” to mean “I’m travelling by car”)
Border and Sentence Intention signals: using emoji both to clarify the tone of the preceding sentence and also to show that the sentence is over, often replacing the final punctuation marks.
Based on an analysis of a Swiss German Whatsapp corpus, the authors conclude that the final category is far and away the most popular, and that emoji rarely replace any part of the lexical parts of a message.
Na’aman et al, 2017:
Na’aman and co-authors also develop a hierarchy of emoji usage, with three top-level categories: Function, Content (both of which would fall under mostly under the ideogram category in Dürscheid & Siever’s classifications) and Multimodal.
Function: Emoji replacing function words, including prepositions, auxiliary verbs, conjunctions, determinatives and punctuation. An example of this category would be “I like 🍩 you”, to be read as “I do not like you”.
Content: Emoji replacing content words and phrases, including nouns, verbs, adjectives and adverbs. An example of this would be “The 🔑 to success”, to be read as “the key to success”.
Multimodal: These emoji “enrich a grammatically-complete text with markers of
affect or stance”. These would fall under the category of border signals in Dürscheid & Siever’s framework, but Na’aman et all further divide these into four categories: attitude, topic, gesture and other.
Based on analysis of a Twitter corpus made of up of only tweets containing emoji, the authors find that multimodal emoji encoding attitude are far and away the most common, making up over 50% of the emoji spans in their corpus. The next most common uses of emoji are to multimodal:topic and multimodal:gesture. Together, these three categories account for close to 90% of the all the emoji use in the corpus, corroborating the findings of Dürscheid & Siever.
Wood & Ruder, 2016:
Wood and Ruder provide further evidence that emoji are used to express emotion (or “attitude”, in Na’aman et al’s terms). They found a strong correlation between the presence of emoji that they had previously determined were associated with a particular emotion, like 😂 for joy or 😭 for sadness, and human annotations of the emotion expressed in those tweets. In addition, an emotion classifier using only emoji as input performed similarly to one trained using n-grams excluding emoji. This provides evidence that there is an established relationship between specific emoji use and expressing emotion.
Donato & Paggio, 2017:
However, the relationship between text and emoji may not always be so close. Donato & Paggio collected a corpus of tweets which contained at least one emoji and that were hand-annotated for whether the emoji was redundant given the text of the tweet. For example, “We’ll always have Beer. I’ll see to it. I got your back on that one. 🍺” would be redundant, while “Hopin for the best 🎓” would not be, since the beer emoji expresses content already expressed in the tweet, while the motorboard adds new information (that the person is hoping to graduate, perhaps). The majority of emoji, close to 60%, were found not to be redundant and added new information to the tweet.
However, the corpus was intentionally balanced between ten topic areas, of which only one was feelings, and as a result the majority of feeling-related tweets were excluded from analysis. Based on this analysis and Wood and Ruder’s work, we might hypothesize that feelings-related emoji may be more redundant than other emoji from other semantic categories.
Barbieri et al, 2017:
Additional evidence for the idea that emoji, especially those that show emotion, are predictable given the text surrounding them comes from Barbieri et al. In their task, they removed the emoji from a thousand tweets that contained one of the following five emoji: 😂, ❤️, 😍, 💯 or 🔥. These emoji were selected since they were the most common in the larger dataset of half a million tweets. Then then asked human crowd workers to fill in the missing emoji given the text of the tweet, and trained a character-level bidirectional LSTM to do the same task. Both humans and the LSTM performed well over chance, with an F1 score of 0.50 for the humans and 0.65 for the LSTM.
So that was a lot of papers and results I just threw at you. What’s the big picture? There are two main points I want you to take away from this post:
People mostly use emoji to express emotion. You’ll see people playing around more than that, sure, but by far the most common use is to make sure people know what emotion you’re expressing with a specific message.
Emoji, particularly emoji that are used to represent emotions, are predictable given the text of the message. It’s pretty rare for us to actually use emoji to introduce new information, and we generally only do that when we’re using emoji that have a specific, transparent meaning.
If you’re interested in reading more, here are all the papers I mentioned in this post:
This blog post is a little different from my usual stuff. It’s based on a talk I gave yesterday at the first annual Data Institute Conference. As a result, it’s aimed at a slightly more technical audience than my usual stuff, but I hope I’ve done an ok job keeping it accessible. Feel free to drop me a comment if you have any questions or found anything confusing and I’ll be sure to help you out.
You can play with the code yourself by forking this notebook on Kaggle (you don’t even have to download or install anything :).
As a result, any large sample of user-generated text is almost guaranteed to have multiple languages in it. So what can you do about it? There are a couple options:
Ignore it
Only look at the parts of the data that are in English
Break the data apart by language & use language-specific tools when available
Let’s take a quick look at the benefits and drawbacks of each approach.
# import libraries we'll useimportspacy# fast NLPimportpandasaspd# dataframesimportlangid# language identification (i.e. what language is this?)fromnltk.classify.textcatimportTextCat# language identification from NLTKfrommatplotlib.pyplotimportplot# not as good as ggplot in R :p
To explore working with multilingual data, let’s look a real-life dataset of user-generated text. This dataset contains 10,502 tweets, randomly sampled from all publicly available geotagged Twitter messages. It’s a realistic cross-section of the type of linguistic diversity you’ll see in a large text dataset.
# read in our datatweetsData=pd.read_csv("../input/all_annotated.tsv",sep="\t")# check out some of our tweetstweetsData['Tweet'][0:5]
0 Bugün bulusmami lazimdiii
1 Volkan konak adami tribe sokar yemin ederim :D
2 Bed
3 I felt my first flash of violence at some fool...
4 Ladies drink and get in free till 10:30
Name: Tweet, dtype: object
Maybe you’ve got a deadline coming up fast, or maybe you didn’t get a chance to actually look at some of your text data and just decide to treat it as if it were English. What could go wrong?
To find out, let’s use Spacy to tokenize all our tweets and take a look at the longest tokens in our data.
Spacy is an open-source NLP library that is much faster than the Natural Language Toolkit, although it does not have as many tasks implemented. You can find more information in the Spacy documentation.
# create a Spacy document of our tweets# load an English-language Spacy modelnlp=spacy.load("en")# apply the english language model to our tweetsdoc=nlp(' '.join(tweetsData['Tweet']))
Now let’s look at the longest tokens in our Twitter data.
The five longest tokens are entire tweets, four produced by an art bot that tweets hashes of Unix timestamps and one that’s just the HTML version of “<3” tweeted a bunch of times. In other words: normal Twitter weirdness. This is actual noise in the data and can be safely discarded without hurting downstream tasks, like sentiment analysis or topic modeling.
The next five longest tokens are also whole tweets which have been identified as single tokens. In this case, though, they were produced by humans!
The tokenizer (which assumes it will be given mainly English data) fails to correct tokenize these tweets because it’s looking for spaces. These tweets are in Japanese, though, and like many Asian languages (including all varieties of Chinese, Korean and Thai) they don’t actually use spaces between words.
In case you’re curious, “、” and “。” are single characters and don’t contain spaces! They are, respectively, the ideographic comma and ideographic full stop, and are part of a very long list of line breaking characters associated with specific orthographic systems.
In order to correctly tokenize Japanese, you’ll need to use a language-specific tokenizer.
The takeaway: if you ignore multiple languages, you’ll end up violating the assumptions behind major out-of-the-box NLP tools¶
Option 2: Only look at the parts of the data that are in English¶
So we know that just applying NLP tools designed for English willy-nilly won’t work on multiple languages. So what if we only grabbed the English-language data and then worked with that?
There are two big issues here:
Correctly identifying which tweets are in English
Throwing away data
Correctly identifying which tweets are in English¶
Probably the least time-intensive way to do this is by attempting to automatically identify the language that each Tweet is written in. A BIG grain of salt here: automatic language identifiers are very error prone, especially on very short texts. Let’s check out two of them.
LangID: Lui, Marco and Timothy Baldwin (2011) Cross-domain Feature Selection for Language Identification, In Proceedings of the Fifth International Joint Conference on Natural Language Processing (IJCNLP 2011), Chiang Mai, Thailand, pp. 553—561. Available from http://www.aclweb.org/anthology/I11-1062
TextCat: Cavnar, W. B. and J. M. Trenkle, “N-Gram-Based Text Categorization” In Proceedings of Third Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, UNLV Publications/Reprographics, pp. 161-175, 11-13 April 1994.
First off, here are the languages the first five tweets are actually written in, hand tagged by a linguist (i.e. me):
Turkish
Turkish
English
English
English
Now let’s see how well two popular language identifiers can detect this.
# summerize the labelled languagetweetsData['Tweet'][0:5].apply(langid.classify)
LangID does…alright, with three out of five tweets identified correctly. While it’s pretty good at identifying English, the first tweet was identified as Azerbaijani and the second tweet was labeled as Malay, which is very wrong (not even in the same language family as Turkish).
Let’s look at another algorithm, TextCat, which is based on character-level N-Grams.
# N-Gram-Based Text Categorizationtc=TextCat()# try to identify the languages of the first five tweets againtweetsData['Tweet'][0:5].apply(tc.guess_language)
0 tur
1 ind
2 bre
3 eng
4 eng
Name: Tweet, dtype: object
TextCat also only got three out of the five correct. Oddly, it identifier “bed” as Breton. To be fair, “bed” is the Breton word for “world”, but it’s still a bit odd.
The takeaway: Automatic language identification, especially on very short texts, is very error prone. (I’d recommend using multiple language identifiers & taking the majority vote.)¶
Even if language identification were very accurate, how much data would be just be throwing away if we only looked at data we were fairly sure was English?
Note: I’m only going to LangID here for time reasons, but given the high error rate I’d recommend using multiple language identification algorithms.
# get the language id for each textids_langid=tweetsData['Tweet'].apply(langid.classify)# get just the language labellangs=ids_langid.apply(lambdatuple:tuple[0])# how many unique language labels were applied?print("Number of tagged languages (estimated):")print(len(langs.unique()))# percent of the total dataset in Englishprint("Percent of data in English (estimated):")print((sum(langs=="en")/len(langs))*100)
Number of tagged languages (estimated):
95
Percent of data in English (estimated):
40.963625976
Only 40% of our data has been tagged as English by LangId. If we throw the rest of it, we’re going to lose more than half of our dataset! Especially if this is data you spent a lot of time and money collecting, that seems downright wasteful. (Plus, it might skew our analysis.)
So if 40% of our data is in English, what is the other 60% made up of? Let’s check out the distribution data across languages in our dataset.
# convert our list of languages to a dataframelangs_df=pd.DataFrame(langs)# count the number of times we see each languagelangs_count=langs_df.Tweet.value_counts()# horrible-looking barplot (I would suggest using R for visualization)langs_count.plot.bar(figsize=(20,10),fontsize=20)
There’s a really long tail on our dataset; most that were identified in our dataset were only identified a few times. This means that we can get a lot of mileage out of including just a few more popular languages in our analysis. How much will we gain, exactly?
print("Languages with more than 400 tweets in our dataset:")print(langs_count[langs_count>400])print("")print("Percent of our dataset in these languages:")print((sum(langs_count[langs_count>400])/len(langs))*100)
Languages with more than 400 tweets in our dataset:
en 4302
es 1020
pt 751
ja 436
tr 414
id 407
Name: Tweet, dtype: int64
Percent of our dataset in these languages:
69.7962292897
By including only five more languages in our analysis (Spanish, Portugese, Japanese, Turkish and Indonesian) we can increase our coverage of the data in our dataset by almost a third!
The takeaway: Just incorporating a couple more languages in your analysis can give you access to a lot more data!¶
Option 3: Break the data apart by language & use language-specific tools¶
Ok, so what exactly does this pipeline look like? Let’s look at just the second most popular language in our dataset: Spanish. What happens when we pull out just the Spanish tweets & tokenize them?
# get a list of tweets labelled "es" by langidspanish_tweets=tweetsData['Tweet'][langs=="es"]# load a Spanish-language Spacy modelfromspacy.esimportSpanishnlp_es=Spanish(path=None)# apply the Spanish language model to our tweetsdoc_es=nlp_es(' '.join(spanish_tweets))# print the longest tokenssorted(doc_es,key=len,reverse=True)[0:5]
This time, the longest tokens are Spanish-language hashtags. This is exactly the sort of thing we’d expect to see! From here, we can use this tokenized dataset to feed into other downstream like sentiment analysis.
Of course, it would be impractical to do this for every single language in our dataset, even if we could be sure that they were all identified correctly. You’re probably going to have to accept that you probably won’t be able to consider every language in your dataset unless you can commit a lot of time. But including any additional language will enrich your analysis!
The takeaway: It doesn’t have to be onerous to incorporate multiple languages in your analysis pipeline!¶
So let’s review our options for analyzing multilingual data:¶
Option 1: Ignore Multilingualism
As we saw, this option will result in violating a lot of the assumptions built into NLP tools (e.g. there are spaces between words). If you do this, you’ll end up with a lot of noise and headaches as you try to move through your analysis pipeline.
Option 2: Only look at English
In this dataset, only looking at English would have led to us throwing away over half of our data. Especailly as NLP tools are developed and made avaliable for more and more languages, there’s less reason to stick to English-only NLP.
Option 3: Seperate your data by language & analyze them independently
This does take a little more work than the other options… but not that much more, especially for languages that already have resources avalialbe for them.
In the course of my day-to-day work on Kaggle’s public data platform, I’ve learned a lot about the ecosystem of language data on the web (or at least the portions of it that have been annotated in English). For example, I’ve noticed a weird disconnect between European and American data repositories resources that I’m pretty sure has its roots in historical and disciplinary divisions.
I’ve also found a lot of great resources, though! At some point, I started keeping notes on interesting data repositories and link aggregators. I finally got around to tidying up and annotating my list of resources, and I figured that it would a useful thing to share with everyone. So, without further ado, here’s an (incomplete) list of some places to find language resources on the web:
The Linguistic Data Consortium is an international non-profit that offers archival hosting of datasets. The data offered by them is high quality and usually not free (although they offer data grants for students).
Kaggle’s public data platform has a lot of language/NLP datasets available on it, many not in English. You can also do data analysis on Kaggle (with R or Python) without having to download anything or set up a local environment.
Like a digital object identifier (DOI) for language resources. Not the best search (only looks at the title) but if you have a specific phrase you’re looking for it can be a good way to discover new resources.
Freesound is a collaborative database of Creative Commons Licensed sounds. Note that some of the speech is synthetic. Helpful automatic annotation utilities can be found here: https://github.com/CrowdTruth/VU-Sound-Corpus/tree/v1.0
In this first part of this two-post series, I looked at how “a male” and “a female” were used on Twitter. I found that one part of speech tagger tagged “male” as a proper noun really frequently (which is weird, cause it isn’t one) and that overall the phrase “a female” was waaaay more frequent. Which is interesting in itself, since my initial question was “are these terms used differently?” and these findings suggest that they are. But the second question is how are these terms used differently? To answer this, we’ll need to get a little more qualitative with it.
“Male” and “female” are fine for ducks, but a little weird for humans.Using the same set of tweets that I collected last time, I randomly selected 100 tweets each from the “a male” and “a female” dataset. Then I hand tagged each subset of tweets for two things: the topic of the tweet (who or what was being referred to as “male” or “female”) and the part of speech of “male” or “female”.
Who or what is being called “male” or “female”?
Because there were so few tweets to analyze, I could do a content analysis. This is a methodology that is really useful when you don’t know for sure ahead of time what types of categories you’re going to see in your data. It’s like clustering that a human does.
Going into this analysis, I thought that there might be a difference between these datasets in terms of how often each term was used to refer to an animal, so I tagged tweets for that. But as I went through the tweets, I was floored by the really high number of tweets talking about trans people, especially Mack Beggs, a trans man from Texas who was forced to wrestle in the women’s division. Trans men were referred to as “a male” really, really often. While there wasn’t a reliable difference between how often “a female” and “a male” was used to refer to animals or humans, there was a huge difference in terms of how often they were used to refer to trans people. “A male” was significantly more likely to be used to describe a trans person than “a female” (X2 (2, N = 200) = 55.33, p <.001.)
Part of Speech
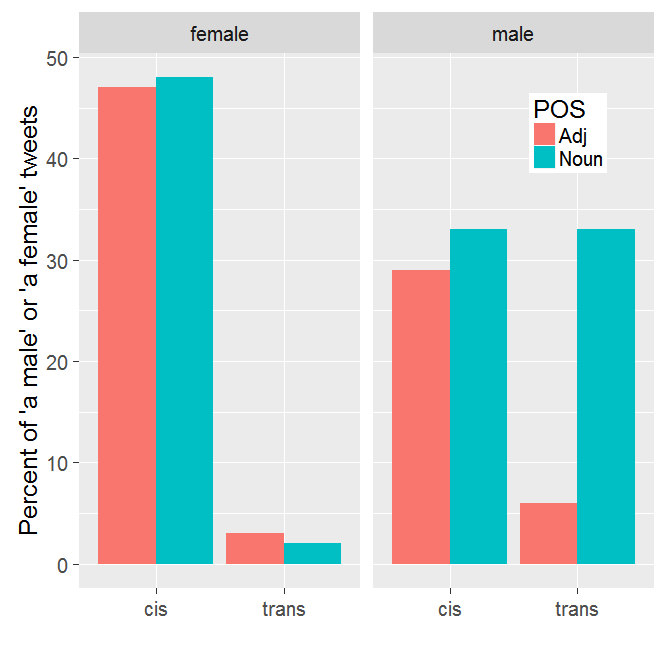
Since the part of speech taggers I used for the first half of my analysis gave me really mixed results, I also hand tagged the part of speech of “male” or “female” in my samples. In line with my predictions during data collection, the only parts of speech I saw were nouns and adjectives.
When I looked at just the difference between nouns and adjectives, there was a little difference, but nothing dramatic. Then, I decided to break it down a little further. Rather than just looking at the differences in part of speech between “male” and “female”, I looked at the differences in part of speech and whether the tweet was about a trans person or a cis (not trans) person.
For tweets with “female”, it was used as a noun and an adjective at pretty much the same rates regardless of whether someone was talking about a trans person or a cis (non-trans) person. For tweets with “male”, though, when the tweet was about a trans person, it was used almost exclusively as a noun.
And there was a huge difference there. A large majority of tweets with “a male” and talking about a trans person used “male” as a noun. In fact, more than a third of my subsample of tweets using “a male” were using it as a noun to talk about someone who was trans.
So what’s going on here? This construction (using “male” or “female” as a noun to refer to a human) is used more often to talk about:
Women. (Remember that in the first blog post looking at this, I found that “a female” is twice a common as “a male.)
Trans men.
These both make sense if you consider the cultural tendency to think about cis men as, in some sense, the “default”. (Deborah Tannen has a really good discussion of this her article “Marked Women, Unmarked Men“. “Marked” is a linguistics term which gets used in a lot of ways, but generally means something like “not the default” or “the weird one”.) So people seem to be more likely to talk about a person being “a male” or “a female” when they’re talking about anyone but a cis man.
A note on African American English
I should note that many of the tweets in my sample were African American English, which is not surprising given the large Black community on Twitter, and that use of “female” as a noun is a feature of this variety. However, the parallel term used to refer to men in this variety is not “a man” or even “a male”, but rather “nigga”, with that spelling. This is similar to “dude” or “guy”: a nonspecific term for any man, regardless of race, as discussed at length by Rachel Jeantal here. You can see an example of this usage in speech above (as seen in the Netflix show “The Unbreakable Kimmy Schmidt“) or in this vine. (I will note, however, that it only has this connotation if used by a speaker of African American English. Borrowing it into another variety, especially if the speaker is white, will change the meaning.)
Now, I’m not a native user of African American English, so I don’t have strong intuitions about the connotation of this usage. Taylor Amari Little (who you may know from her TEDx talk on Revolutionary Self-Produced Justice) is, though, and tweeted this (quoted with permission):
And this does square with my own intuitions: there’s something slightly sinister about someone who refers to women exclusively as “females”. As journalist Vonny Moyes pointed out in her recent coverage of ads offering women free rent in exchange for sexual favors, they almost refer to women as “girls or females – rarely ever women“. Personally, I find that very good motivation not to use “a male” or “a female” to talk about any human.
I recently read a very interesting article on the design of aspects of choosing a wake word, the word you use to turn on a voice-activated system. In Star Trek it’s “Computer”, but these days two of the more popular ones are “Alexa” and “OK Google”. The article’s author was a designer and noted that she found “Ok Google” or “Hey Google” to be more pleasant to use than “Alexa”. As I was reading the comments (I know, I know) I noticed that a lot of the people who strongly protested that they preferred “Alexa” had usernames or avatars that I would associate with male users. It struck me that there might be an underlying social pattern here.
So, being the type of nerd I am, I whipped up a quick little survey to look at the interaction between user gender and their preference for wake words. The survey only had two questions:
What is your gender?
Male
Female
Other
If Google Home and the Echo offered identical performance in all ways except for the wake word (the word or phrase you use to wake the device and begin talking to it), which wake word would you prefer?
“Ok Google” or “Hey Google”
“Alexa”
I included only those options becuase those are the defaults–I am aware you can choose to change the Echo’s wake word. (And probably should, given recent events.) 67 people responded to my survey. (If you were one of them, thanks!)
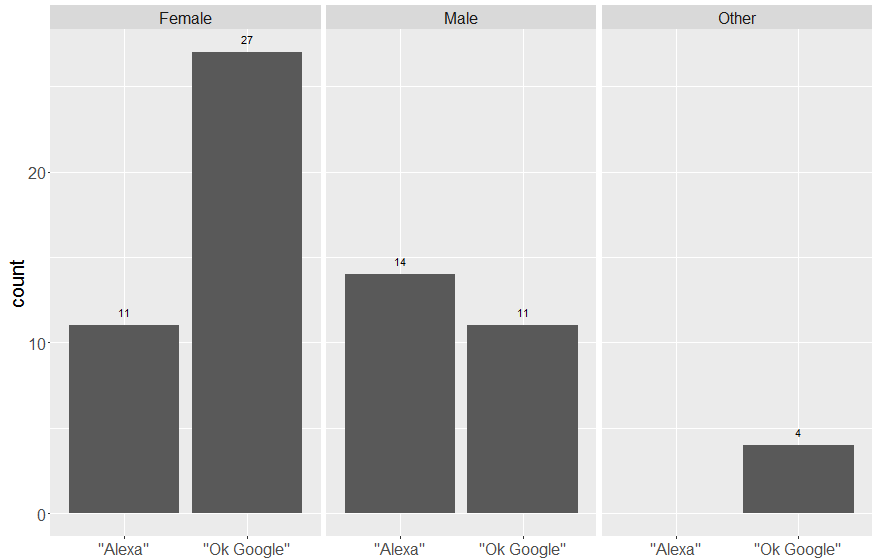
So what were the results? They were actually pretty strongly in line with my initial observations: as a group, only men preferred “Alexa” to “Ok Google”. Furthermore, this preference was far weaker than people of other genders’ for “Ok Google”. Women preferred “Ok Google” at a rate of almost two-to-one, and no people of other genders preferred “Alexa”.
I did have a bit of a skewed sample, with more women than men and people of other genders, but the differences between genders were robust enough to be statistically significant (c2(2, N = 67) = 7.25, p = 0.02)).
Women preferred “Ok Google” to “Alexa” 27:11, men preferred “Alexa” to “Ok Google” 14:11, and the four people of other genders in my survey all preferred “Ok Google”.
So what’s the take-away? Well, for one, Johna Paolino (the author of the original article) is by no means alone in her preference for a non-gendered wake word. More broadly, I think that, like the Clippy debacle, this is excellent evidence that there are strong gendered differences in how users’ gender affects their interaction with virtual agents. If you’re working to create virtual agents, it’s important to consider all types of users or you might end up creating something that rubs more than half of your potential customers the wrong way.
So if you’re like me, you sometimes take notes on the computer and end up using some shortcuts so you can keep up with the speed of whoever’s talking. One of the short cuts I use a lot is replacing the word “and” with punctuation. When I’m handwriting things I only ever use “+” (becuase I can’t reliably write an ampersand), but in typing I use both “+” and “&”. And I realized recently, after going back to change which one I used, that I had the intuition that they should be used for different things.
I don’t use Ampersands when I’m handwriting things becuase they’re hard to write.
Like sometimes happens with linguistic intuitions, though, I didn’t really have a solid idea of how they were different, just that they were. Fortunately, I had a ready-made way to figure it out. Since I use both symbols on Twitter quite a bit, all I had to do was grab tweets of mine that used either + or & and figure out what the difference was.
I got 450 tweets from between October 7th and November 11th of this year from my own account (@rctatman). I used either & or + in 83 of them, or roughly 18%. This number is a little bit inflated because I was livetweeting a lot of conference talks in that time period, and if a talk has two authors I start every livetweet from that talk with “AuthorName1 & AuthorName2:”. 43 tweets use & in this way. If we get rid of those, only around 8% of my tweets contain either + or &. They’re still a lot more common in my tweets than in writing in other genres, though, so it’s still a good amount of data.
So what do I use + for? See for yourself! Below are all the things I conjoined with + in my Twitter dataset. (Spelling errors intact. I’m dyslexic, so if I don’t carefully edit text—and even sometimes when I do, to my eternal chagrin—I tend to have a lot of spelling errors. Also, a lot of these tweets are from EMNLP so there’s quite a bit of jargon.)
time + space
confusable Iberian language + English
Data + code
easy + nice
entity linking + entity clustering
group + individual
handy-dandy worksheet + tips
Jim + Brenda, Finn + Jake
Language + action
linguistic rules + statio-temporal clustering
poster + long paper
Ratings + text
static + default methods
syntax thing + cattle
the cooperative principle + Gricean maxims
Title + first author
to simplify manipulation + preserve struture
If you’ve had some syntactic training, it might jump out to you that most of these things have the same syntactic structure: they’re noun phrases! There are just a couple of exception. The first is “static + default methods”, where the things that are being conjoined are actually adjectives modifying a single noun. The other is “to simplify manipulation + preserve struture”. I’m going to remain agnostic about where in the verb phrase that coordination is taking place, though, so I don’t get into any syntax arguments ;). That said, this is a fairly robust pattern! Remember that I haven’t been taught any rules about what I “should” do, so this is just an emergent pattern.
Ok, so what about &? Like I said, my number one use is for conjunction of names. This probably comes from my academic writing training. Most of the papers I read that use author names for in-line citations use an & between them. But I do also use it in the main body of tweets. My use of & is a little bit harder to characterize, so I’m going to go through and tell you about each type of thing.
First, I use it to conjoin user names with the @ tag. This makes sense, since I have a strong tendency to use & with names:
@uwengineering & @uwnlp
@amazon @baidu @Grammarly & @google
In some cases, I do use it in the same way as I do +, for conjoining noun phrases:
Q&A
the entities & relations
these features & our corpus
LSTM & attention models
apples & concrete
context & content
But I also use it for comparatives:
Better suited for weak (bag-level) labels & interpretable and flexible
easier & faster
And, perhaps more interestingly, for really high-level conjugation, like at the level of the sentence or entire verb phrase (again, I’m not going to make ANY claims about what happens in and around verbs—you’ll need to talk to a syntactician for that!).
Classified as + or – & then compared to polls
in 30% of games the group performance was below average & in 17% group was worse than worst individual
math word problems are boring & kids learn better if they’re interested in the theme of the problem
our system is the first temporal tagger designed for social media data & it doesn’t require hand tagging
use a small labeled corpus w/ small lexicon & choose words with high prob. of 1 label
And, finally, it gets used in sort of miscellaneous places, like hashtags and between URLs.
So & gets used in a lot more places than + does. I think that this is probably because, on some subconscious level I consider & to be the default (or, in linguistics terms, “unmarked“). This might be related to how I’m processing these symbols when I read them. I’m one of those people who hears an internal voice when reading/writing, so I tend to have canonical vocalizations of most typed symbols. I read @ as “at”, for example, and emoticons as a prosodic beat with some sort of emotive sound. Like I read the snorting emoji as the sound of someone snorting. For & and +, I read & as “and” and + as “plus”. I also use “plus” as a conjunction fairly often in speech, as do many of my friends, so it’s possible that it may pattern with my use in speech (I don’t have any data for that, though!). But I don’t say “plus” nearly as often as I say “and”. “And” is definitely the default and I guess that, by extension, & is as well.
Another thing that might possibly be at play here is ease of entering these symbols. While I’m on my phone they’re pretty much equally easy to type, on a full keyboard + is slightly easier, since I don’t have to reach as far from the shift key. But if that were the only factor my default would be +, so I’m fairly comfortable claiming that the fact that I use & for more types of conjunction is based on the influence of speech.
A BIG caveat before I wrap up—this is a bespoke analysis. It may hold for me, but I don’t claim that it’s the norm of any of my language communities. I’d need a lot more data for that! That said, I think it’s really neat that I’ve unconsciously fallen into a really regular pattern of use for two punctuation symbols that are basically interchangeable. It’s a great little example of the human tendency to unconsciously tidy up language.









_(8250815324).jpg)