
Earlier this summer, I gave a talk on the promise & pitfalls of social media data for the Joint Statistical Meetings. While I don’t think there’s a recording of the talk, enough people asked for one that I figured it would be worth putting together a blog post version of the talk. Enjoy!
What you can do with social media data
Let’s start with the good news: research using social media data has revolutionized social science research. It’s let us ask bigger question more quickly, helped us overcome some of the key drawbacks of behavioral experimental work and ask new kinds of questions.
More data faster
I can’t overstate how revolutionary the easy availability of social media data has been, especially in linguistics. It has increased both the rate and scale of data collection by orders of magnitude. Compare the time it took to compare the Dictionary of American Regional English (DARE) to the Wordmapper app below. The results are more or less the same, maps of where in the US folks use different words (in this example, “cellar”). But what once took the entire careers of multiple researchers can now be done in a few months, and with far higher resolution.
| Dictionary of American Regional English (DARE) | Word Mapper App | |
| Data collection | 48 years (1965 – 2013) | <1 year |
| Size of team | 2,777 people | 4 people |
| Number of participants | 1,843 people | 20 million |
 |
 |
Social networks
Social media sites with a following or friend feature also let us ask really large scale questions about social networks. How do social networks and political affiliation interact? How does language change move through a social network? What characteristics of social network structure are more closely associated with the spread of misinformation? Of course, we could ask these questions before social media data… but by using APIs to access social media data, we reduce the timescale of these projects from decades to weeks or even days and we have a clear way to operationalize social network ties. It’s fairly hard for someone to sit down and list everyone they interact with face-to-face, but it’s very easy to grab a list of all the Twitter accounts you follow.
Wild-caught, all natural data
One of the constant struggles in experimental work is the fact that the mere fact of being observed changes behavior. This is known as the Hawthorne Effect in psychology or the Observer’s Paradox in sociolinguistics. As a result, even the most well-designed experiment is limited by the fact that the participants know that they are completing an experiment.
Social media data, however, doesn’t have this limitation. Since most social media research projects are conducted on public data without interacting directly with participants, they are not generally considered human subjects research. When you post something on a public social media account, you don’t have a reasonable expectation of privacy. In other words, you know that just anyone could come along and read it, and that includes researchers. As a result it is not generally necessary to collect informed consent for social media projects. (Informed consent is when you are told exactly what’s going to happen during an experiment you’re participating, and you agree to participate in it.) This means that the vast majority of folks who are participating in a social media study don’t actually know that they’re part of a study.
The benefit of this is that it allows researchers to get around three common confounds that plague social science research:
- Bradley effect: People tend to tell researchers what they think they want to hear
- Response bias: The sample of people willing to do an experiment/survey differ in a meaningful way from the population as a whole
- Observer’s paradox/Hawthorne effect: People change their behavior when they know they’re being observed
While this is a boon to researchers, the lack of informed consent does introduce other other problems, which we’ll talk about later.
What you can’t do with social media data
Of course, all the benefits of social media come at a cost. There are several key drawbacks and limitations of social media research:
- You can’t be sure who your participants are.
- There’s inherent sampling bias.
- You can’t violate the developer’s agreements.
You’re not sure who you’re studying…
Because you don’t meet with the people whose data is included in your study, you don’t know for sure what sorts of demographic categories they belong to, whether they are who they’re claiming to be or even if they’re human at all. You have to deal with both bots, accounts where content is produced and distributed automatically by a computer and sock puppets, where one person pretends to be another person. Sock puppets in particular can be very difficult to spot and may skew your results in unpredictable ways.
…but you can be sure your sample is biased.
Social media users aren’t randomly drawn from the world’s population as a whole. Social media users tend to be WEIRD: from wealthy, educated, industrialized, rich and democratic societies. This group is already over-represented in social science and psychology research studies, which may be subtly skewing our models of human behavior.
In addition, different social media platforms have different user bases. For example, Instagram and Snapchat tend to have younger users, Pinterest has more women (especially compared to Reddit, which skews male) and LinkedIn users tend to be highly educated and upper middle class. And that doesn’t even get to social network effects: you’re more likely to be on the same platform your friends are on, and since social networks tend to be homophilous, you can end up with pockets of very socially homogeneous folks. So, even if you manage to sample randomly from a social media platform, your sample is likely to differ from one taken from the population as a whole.
You need to abide by the developer’s agreements for whatever platform you’re using data from.
This is mainly an issue if you’re using API (application programmatic interface) to fetch data from a service. Developer’s agreements vary between platforms, but most limit the amount of data you can fetch and store, and how and if you can share it with other researchers. For example, if you’re sharing Twitter data you can only share 50,000 tweets at a time and even then only if you have to have people download a file by clicking on it. If you share any more than that, you should just share the ID’s of the tweets rather than the full tweets. (Document the Now’s Hydrator can help you fetch the tweets associated with a set of IDs.)
What you shouldn’t do with social media data
Finally, there are ethical restrictions on what we should do with social media data. As researchers, we need to 1) respect the wishes of users and 2) safeguard their best interests, especially given that we don’t (currently) generally get informed consent from the folks whose data we’re collecting.
Respecting users’ wishes
At least in the US, ethical human subjects research is led by three guiding principles set forth in the Belmont report. If you’re unfamiliar with the report, it was written in the aftermath of the Tuskegee Valley experiments. These were a series of medical experiments on African Americans men who had contracted syphilis conducted from the 1930’s to 1970’s. During the study, researchers withheld the cure (and even information that it existed) from the participants. The study directly resulted in the preventable deaths of 128 men and many health problems for study participants, their wives and children. It was a clear ethical violation of the human rights of participants and the moral stain of it continues to shape how we conduct human subjects research in the US.
The three principles of ethical human subjects research are:
- Respect for Persons: People should be treated as autonomous individuals and persons with diminished autonomy (like children or prisoners) are entitled to protection.
- Beneficence: 1) Do not harm and 2) maximize possible benefits and minimize possible harms.
- Justice: Both the risks and benefits of research should be distributed equally.
Social media research might not technically fall under the heading of human subjects research, since we aren’t intervening with our participants. However, I still believe that it’s important that researchers following these general guides when designing and distributing experiments.
One thing we can do is respect their wishes of the communities we study. Fortunately, we have some evidence of what those wishes are. Feisler and Proferes (2018) surveyed 368 Twitter users on their perception of a variety of research behaviors.
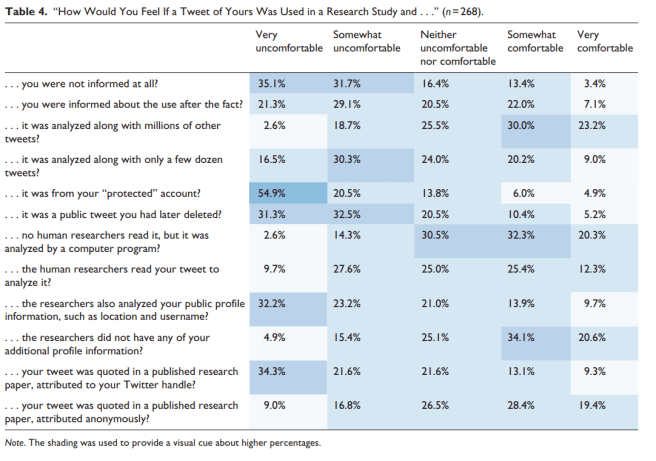
In general, Twitter users are more OK with research with the following characteristics:
- Large datasets
- Analyzed automatically
- Social media users informed about research
- If tweets are quoted, they are anonymized. (Note that if you include the exact text, it’s possible to reverse search the quoted tweet and de-anonymize it. I recommend changing at least 20% of the content words in a tweet to synonyms to get around this and double-checking by trying to de-anonymize it yourself.)
These characteristics, however, are not as acceptable to Twitter users:
- Small datasets
- Analysis done by hand (presumably including analysis by Mechanical Turk workers)
- Tweets from protected accounts or deleted tweets analyzed (which is also against the developer’s agreement, so you shouldn’t be doing this anyway)
- Quoting with citation (very different from academic norms!)
In general, I think these suggest general best practices for researchers working with Twitter data.
- Stick to larger datasets
- Try to automate wherever possible
- Follow the developer’s agreement
- Take anonymity seriously.
There is one thing I disagree with, however: I don’t think we should contact everyone who’s tweets we use in our research.
Should we contact people whose tweets we use in our studies? My gut instinct on this one is “no”. If you’re collecting a large amount of data, you probably shouldn’t reach out to everyone in the data.
For users who don’t have open DM’s, the only way to contact them is to publicly mention them using @username. The problem with this is that it partly de-anonymizes your data. If you then choose to share your data, having publicly shared a list of whose data was included in the dataset it makes it much easier to de-anonymize. Instead of trying to figure out whose tweets were included when looking at all of Twitter, an adversary only has to figure out which of the users on the list you’ve given them is connected to which record.
The main exception to this is if have a project that’s a deep dive on one user, in which case you probably should. (For example, I contacted Chaz Smith and let him know about my phonological analysis of his #pronouncingthingsincorrectly Vines.)
Do no harm
Another aspect of ethical research is trying to ensure that your research or research data doesn’t have potentially unethical applications. The elephant in the room here, of course, is the data Cambridge Analytica collected from Facebook users. Researchers at Cambridge, collecting data for a research project, got lots of people’s permission to access their Facebook data. While that wasn’t a problem, they collected and saved Facebook data from other folks as well, who hadn’t opted in. In the end, only a half of a half of a percent of the folks whose data was in the final dataset actually agreed to be included in it. To make matters worse, this data was used by a commercial company founded by one of the researchers to (possibly) influence elections in the US and UK. Here’s a New York Times article that goes into much more detail. This has understandably lead to increased scrutiny of how social media research data is collected and used.
I’m not bringing this up to call out Facebook in particular, but to explain why it’s important to consider how research data might be used long-term. How and where will it be stored? For how long? Who will have access to it? In short, if you’re a researcher, how can you ensure that data you collected won’t end up somehow hurting the people you collected it from?
As an example of how important these questions are, consider this OK Cupid “research” dataset. It was collected without consent and shared publicly without anonymization. It included many personal details that were only intended to be shared with other users of the site, including explicit statements of sexual orientation. In addition to being an unforgivable breach of privacy, this directly endangered users whose data was collected: information on sexual orientation was shared for people living in countries where homosexuality is a crime that carries a death penalty or sentence of life in prison. I have a lot of other issues with this “study” as well, but the fact that it directly endangered research subjects who had no chance to opt out is by far the most egregious ethical breach.
If you are collecting social media data for research purposes, it is your ethical responsibility to safeguard the well-being of the people whose data you’re using.
I bring up these cautionary tales not to scare you off of social media research but to really impress the gravity of the responsibility you carry as a social media researcher. Social media data has the potential to dramatically improve our understanding of the world. A lot of my own work has relied heavily on it! But it’s important that we, as researchers, take our moral duty to make sure that we don’t end up doing more harm than good very seriously.






_(8250815324).jpg)




{kind=link}
{kind=link}