
Today’s blog post is a bit different. It’s in dance!
If that wasn’t quite clear enough for you, you can check this blog post for a more detailed explanation.
Today’s blog post is a bit different. It’s in dance!
If that wasn’t quite clear enough for you, you can check this blog post for a more detailed explanation.
If you’ve been following my blog for a while, you may remember that last year I found that YouTube’s automatic captions didn’t work as well for some dialects, or for women. The effects I found were pretty robust, but I wanted to replicate them for a couple of reasons:
With that in mind, I did a second analysis on both YouTube’s automatic captions and Bing’s speech API (that’s the same tech that’s inside Microsoft’s Cortana, as far as I know).
For this project, I used speech data from the International Dialects of English Archive. It’s a collection of English speech from all over, originally collected to help actors sound more realistic.
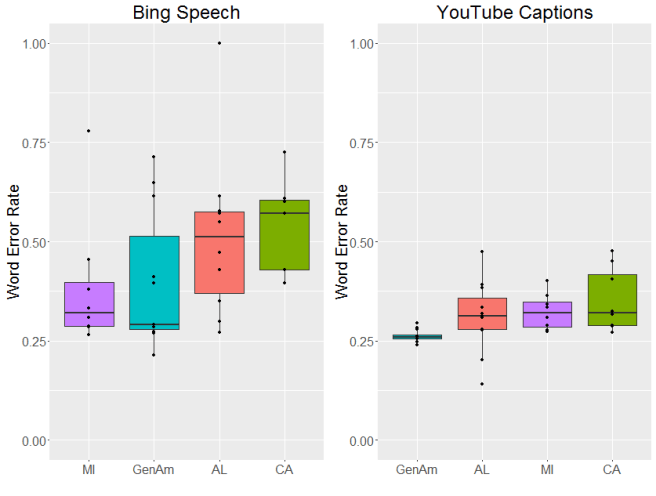
I used speech data from four varieties: the South (speakers from Alabama), the Northern Cities (Michigan), California (California) and General American. “General American” is the sort of news-caster style of speech that a lot of people consider unaccented–even though it’s just as much an accent as any of the others! You can hear a sample here.
For each variety, I did an acoustic analysis to make sure that speakers I’d selected actually did use the variety I thought they should, and they all did.
For the YouTube captions, I just uploaded the speech files to YouTube as videos and then downloaded the subtitles. (I would have used the API instead, but when I was doing this analysis there was no Python Google Speech API, even though very thorough documentation had already been released.)
Bing’s speech API was a little more complex. For this one, my co-author built a custom Android application that sent the files to the API & requested a long-form transcript back. For some reason, a lot of our sound files were returned as only partial transcriptions. My theory is that there is a running confidence function for the accuracy of the transcription, and once the overall confidence drops below a certain threshold, you get back whatever was transcribed up to there. I don’t know if that’s the case, though, since I don’t have access to their source code. Whatever the reason, the Bing transcriptions were less accurate overall than the YouTube transcriptions, even when we account for the fact that fewer words were returned.
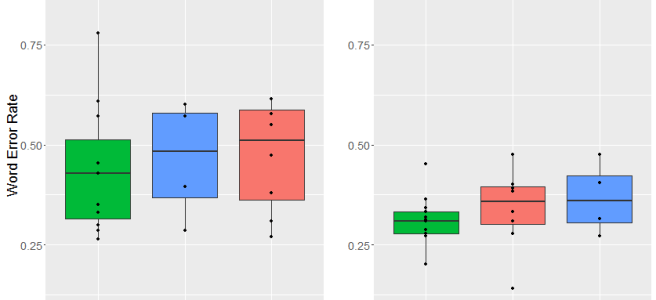
OK, now to the results. Let’s start with dialect area. As you might be able to tell from the graphs below, there were pretty big differences between the two systems we looked at. In general, there was more variation in the word error rate for Bing and overall the error rate tended to be a bit higher (although that could be due to the incomplete transcriptions we mentioned above). YouTube’s captions were generally more accurate and more consistent. That said, both systems had different error rates across dialects, with the lowest average error rates for General American English.
So why did I find an effect last time? My (untested) hypothesis is that there was a difference in the signal to noise ratio for male and female speakers in the user-uploaded files. Since women are (on average) smaller and thus (on average) slightly quieter when they speak, it’s possible that their speech was more easily masked by background noises, like fans or traffic. These files were all recorded in a quiet place, however, which may help to explain the lack of difference between genders.

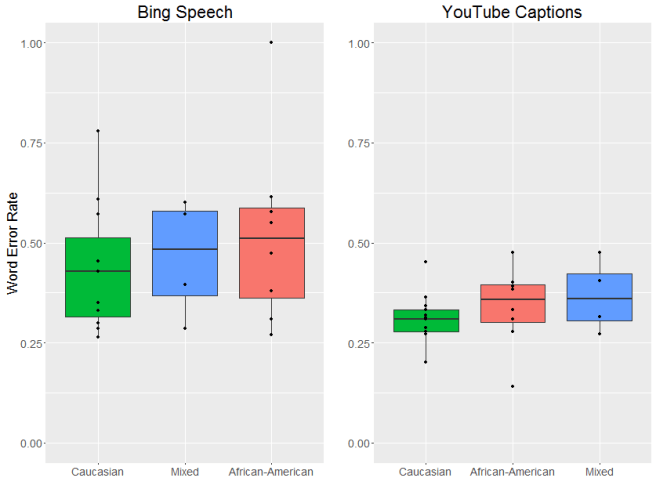
There are two things I’m really worried about with these types of speech recognition errors. The first is higher error rates seem to overwhelmingly affect already-disadvantaged groups. In the US, strong regional dialects tend to be associated with speakers who aren’t as wealthy, and there is a long and continuing history of racial discrimination in the United States.
Given this, the second thing I’m worried about is the fact that these voice recognition systems are being incorporated into other applications that have a real impact on people’s lives.
Every automatic speech recognition system makes errors. I don’t think that’s going to change (certainly not in my lifetime). But I do think we can get to the point where those error don’t disproportionately affect already-marginalized people. And if we keep using automatic speech recognition into high-stakes situations it’s vital that we get to that point quickly and, in the meantime, stay aware of these biases.
If you’re interested in the long version, you can check out the published paper here.

This week, I’m in Vancouver this week for the meeting of the Association for Computational Linguistics. (On the subject of conferences, don’t forget that my offer to help linguistics students from underrepresented minorities with the cost of conferences still stands!) The work I’m presenting is on a new research direction I’m pursuing and I wanted to share it with y’all!
If you’ve read some of my other posts on sociolinguistics, you may remember that the one of its central ideas is that certain types of language usage pattern together with aspects of people’s social identities. In the US, for example, calling a group of people “yinz” is associated with being from Pittsburgh. Or in Spanish, replacing certain “s” sounds with “th” sounds is associated with being from northern or central Spain. When a particular linguistic form is associated with a specific part of someone’s social identity, we call that a “sociolinguistic variable”
There’s been a lot of work on the type of sociolinguistic variables people use when they’re speaking, but there’s been less work on what people do when they’re writing. And this does make a certain amount of sense: many sociolinguistic variables are either 1) something people aren’t aware they’re doing or 2) something that they’re aware they’re doing but might not consider “proper”. As a result, they tend not to show up in formal writing.
This is where the computational linguistics part comes in; people do a lot of informal writing on computers, especially on the internet. In fact, I’d wager that humans are producing more text now than at any other point in history, and a lot of it is produced in public places. That lets us look for sociolinguistics variables in writing in a way that wasn’t really possible before.
Which is a whole lot of background to be able to say: I’m looking at how punctuation and capitalization pattern with political affiliation on Twitter.
Political affiliation is something that other sociolinguists have definitely looked at. It’s also something that’s very, very noticeable on Twitter these days. This is actually a boon to this type of research. One of the hard things about doing research on Twitter is that you don’t always necessarily know someone’s social identity. And if you use a linguistic feature to try to figure out their identity when what you’re interested in is linguistic features, you quickly end up with the problem of circular logic.
Accounts which are politically active, however, will often explicitly state their political affiliation in their Twitter bio. And I used that information to get tweets from people I was very sure had a specific political affiliation.
For this project, I looked at people who use the hashtags #MAGA and #theResistance in their Twitter bios. The former is an initialism for “Make America Great Again” and is used by politically conservative folks who support President Trump. The latter is used by political liberal folks who are explicitly opposed to President Trump. These two groups not only have different political identities, but also are directly opposed to each other. This means there’s good reason to believe that they will use language in different ways that reflect that identity.
But what about the linguistic half of the equation? Punctuation and capitalization are especially interesting to me because they seem to be capturing some of the same information we might find in prosody or intonation in spoken language. Things like YELLING or…pausing….or… uncertainty? They’re also much, much easier to measure punctuation than intonation, which is notoriously difficult and time-consuming to annotate. At the same time, I have good evidence that how you use punctuation and capitalization has some social meaning. Check out this tweet, for example:

So, if punctuation and capitalization are doing something socially, is part of what they’re doing expressing political affiliation?
That’s what I looked into. I grabbed up to 100 tweets each from accounts which used either #MAGA or #theResistance in their Twitter bios. Then I looked at how much punctuation and capitalization users from these two groups used in their tweets.
First, I looked at all punctuation marks. I did find that, on average, liberal users tended to use less punctuation. But when I took a closer look at the data, an interesting pattern emerged. In both the liberal and conservative groups, there were two clusters of users: those who used a lot of punctuation and those who used almost none.
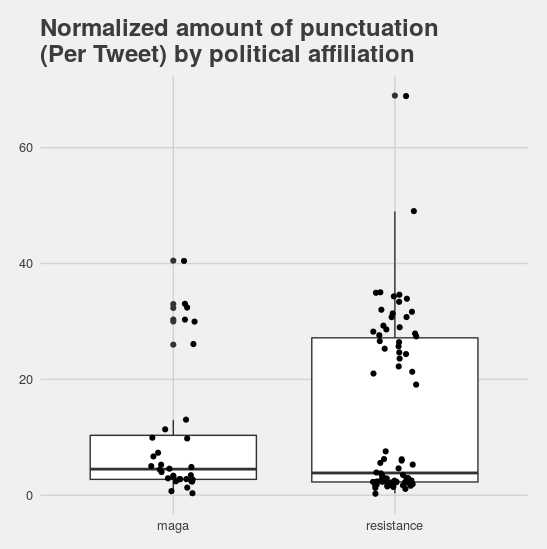
What gives rise to these two clusters? I honestly don’t know, but I do have a hypothesis. I think that there’s probably a second social variable in this data that I wasn’t able to control for. It seems likely that the user’s age might have something to do with it, or their education level, or even whether they use thier Twitter account for professional or personal communication.
My intuition that there’s a second latent variable at work in this data is even stronger given the results for the amount of capitalization folks used. Conservative users tended to use more capitalization than the average liberal user, but there was a really strong bi-modal distribution for the liberal accounts.
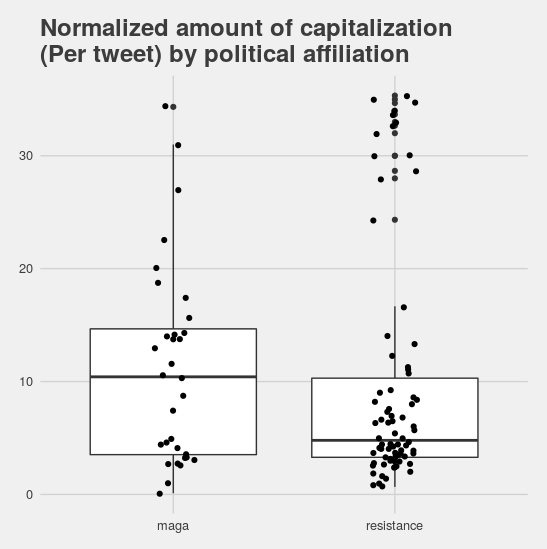
What’s more, the liberal accounts that used a lot of punctuation also tended to use a lot of capitalization. Since these features are both ones that I associate with very “proper” usage (things like always starting a tweet with a capital letter, and ending it with a period) this seems to suggest that some liberal accounts are very standardized in their use of language, while others reject at least some of those standards.
So what’s the answer the question I posed in the title? Can capitalization or punctuation reveal political affiliation? For now, I’m going to go with a solid “maybe”. Users who use very little capitalization and punctuation are more likely to be liberal… but so are users who use a lot of both. And, while I’m on the subject of caveats, keep in mind that I was only looking at very politically active accounts who discuss thier politics in their user bios. These observations probably don’t apply to all Twitter accounts (and certainly not across different languages).
If you’re interested in reading more, you can check out the fancy-pants versions of this research here and here. And I definitely intend to consider looking at this; I’ll keep y’all posted on my findings. For now, however, off to find me a Nanimo bar!
First, the linguist’s answer: none. Zero. Everyone who uses a language uses a variety of that language, one that reflects their social identity–including things like gender, socioeconomic status or regional background.
But the truth is that some people, especially in the US, have the social privileged of being considered “unaccented”. I can’t count how many times I’ve been “congratulated” by new acquaintances on having “gotten rid of” my Virginia accent. The thing is, I do have a lot of linguistic features from Tidewater/Piedmont English, like a strong distinction between the vowels in “body” and “baudy”, “y’all” for the second person plural and calling a drive-through liquor store a “brew thru” (shirts with this guy on them were super popular in my high school). But, at the same time, I also don’t have a lot of strongly stigmatized features, like dropping r’s or strong monopthongization you’d hear from a speaker like Virgil Goode (although most folks don’t really sound like that anymore). Plus, I’m young, white, (currently) urban and really highly educated. That, plus the fact that most people don’t pick up on the Southern features I do have, means that I have the privilege of being perceived as accent-less.
But how many people in the US are in the same boat as I am? This is a difficult question, especially given that there is no wide consensus about what “standard”, or “unaccented”, American English is. There is, however, a lot of discussion about what it’s not. In particular, educated speakers from the Midwest and West are generally considered to be standard speakers by non-linguists. Non-linguists also generally don’t consider speakers of African American English and Chicano English to be “standard” speakers (even though both of these are robust, internally consistent language varieties with long histories used by native English speakers). Fortunately for me, the United States census asks census-takers about their language background, race and ethnicity, educational attainment and geographic location, so I could use census data to roughly estimate how many speakers of “standard” English there are in the United States. I chose to use the 2011 census, as detailed data on language use has been released for that year on a state-by-state basis (you can see a summary here).
From this data, I calculated how many individuals were living in states assigned by the U.S. Census Bureau to either the West or Midwest and how many residents surveyed in these states reported speaking English ‘very well’ or better. Then, assuming that residents of these states had educational attainment rates representative of national averages, I estimated how many college educated (with a bachelor’s degree or above) non-Black and non-Hispanic speakers lived in these areas.
So just how many speakers fit into this “standard” mold? Fewer than you might expect! You can see the breakdown below:
|
Speakers in the 2011 census who… |
Count |
% of US Population |
|
…live in the United States… |
311.7 million |
100% |
|
…and live in the Midwest or West… |
139,968,791 |
44.9% |
|
…and speak English at least ‘very well’… |
127,937,178 |
41% |
|
…and are college educated… |
38,381,153 (estimated) |
12.31% |
|
…and are not Black or Hispanic. |
33,391,603 (estimated) |
10.7% |
I’ll get back to “a male/a female” question in my next blog post (promise!), but for now I want to discuss some of the findings from my dissertation research. I’ve talked about my dissertation research a couple times before, but since I’m going to be presenting some of it in Spain (you can read the full paper here), I thought it would be a good time to share some of my findings.
In my dissertation, I’m looking at how what you think you know about a speaker affects what you hear them say. In particular, I’m looking at American English speakers who have just learned to correctly identify the vowels of New Zealand English. Due to an on-going vowel shift, the New Zealand English vowels are really confusing for an American English speaker, especially the vowels in the words “head”, “head” and “had”.

These overlaps can be pretty confusing when American English speakers are talking to New Zealand English speakers, as this Flight of the Conchords clip shows!
The good news is that, as language users, we’re really good at learning new varieties of languages we already know, so it only takes a couple minutes for an American English speaker to learn to correctly identify New Zealand English vowels. My question was this: once an American English speaker has learned to understand the vowels of New Zealand English, how do they know when to use this new understanding?
In order to test this, I taught twenty one American English speakers who hadn’t had much, if any, previous exposure to New Zealand English to correctly identify the vowels in the words “head”, “heed” and “had”. While I didn’t play them any examples of a New Zealand “hid”–the vowel in “hid” is said more quickly in addition to having different formants, so there’s more than one way it varies–I did let them say that they’d heard “hid”, which meant I could tell if they were making the kind of mistakes you’d expect given the overlap between a New Zealand “head” and American “hid”.
So far, so good: everyone quickly learned the New Zealand English vowels. To make sure that it wasn’t that they were learning to understand the one talker they’d been listening to, I tested half of my listeners on both American English and New Zealand English vowels spoken by a second, different talker. These folks I told where the talker they were listening to was from. And, sure enough, they transferred what they’d learned about New Zealand English to the new New Zealand speaker, while still correctly identifying vowels in American English.
The really interesting results here, though, are the ones that came from the second half the listeners. This group I lied to. I know, I know, it wasn’t the nicest thing to do, but it was in the name of science and I did have the approval of my institutional review board, (the group of people responsible for making sure we scientists aren’t doing anything unethical).
In an earlier experiment, I’d played only New Zealand English as this point, and when I told them the person they were listening to was from America, they’d completely changed the way they listened to those vowels: they labelled New Zealand English vowels as if they were from American English, even though they’d just learned the New Zealand English vowels. And that’s what I found this time, too. Listeners learned the New Zealand English vowels, but “undid” that learning if they thought the speaker was from the same dialect as them.
But what about when I played someone vowels from their own dialect, but told them the speaker was from somewhere else? In this situation, listeners ignored my lies. They didn’t apply the learning they’d just done. Instead, the correctly treated the vowels of thier own dialect as if they were, in fact, from thier dialect.
At first glance, this seems like something of a contradiction: I just said that listeners rely on social information about the person who’s talking, but at the same time they ignore that same social information.
So what’s going on?
I think there are two things underlying this difference. The first is the fact that vowels move. And the second is the fact that you’ve heard a heck of a lot more of your own dialect than one you’ve been listening to for fifteen minutes in a really weird training experiment.
So what do I mean when I say vowels move? Well, remember when I talked about formants above? These are areas of high acoustic energy that occur at certain frequency ranges within a vowel and they’re super important to human speech perception. But what doesn’t show up in the plot up there is that these aren’t just static across the course of the vowel–they move. You might have heard of “diphthongs” before: those are vowels where there’s a lot of formant movement over the course of the vowel.
And the way that vowels move is different between different dialects. You can see the differences in the way New Zealand and American English vowels move in the figure below. Sure, the formants are in different places—but even if you slid them around so that they overlapped, the shape of the movement would still be different.

Ok, so the vowels are moving in different ways. But why are listeners doing different things between the two dialects?
Well, remember how I said earlier that you’ve heard a lot more of your own dialect than one you’ve been trained on for maybe five minutes? My hypothesis is that, for the vowels in your own dialect, you’re highly attuned to these movements. And when a scientist (me) comes along and tells you something that goes against your huge amount of experience with these shapes, even if you do believe them, you’re so used to automatically understanding these vowels that you can’t help but correctly identify them. BUT if you’ve only heard a little bit of a new dialect you don’t have a strong idea of what these vowels should sound like, so if you’re going to rely more on the other types of information available to you–like where you’re told the speaker is from–even if that information is incorrect.
So, to answer the question I posed in the title, can what you think you know about someone affect how you hear them? Yes… but only if you’re a little uncertain about what you heard in the first place, perhaps becuase it’s a dialect you’re unfamiliar with.
From the title, you might think this is a US-centric post. To a certain extent, it is. But I’m also going to be talking about topics that are more broadly of interest: what are some specific benefits of humanities research? And who should fund basic research? A lot has been written about these topics generally, so I’m going to be talking about linguistics and computational linguistics specifically.
This blog post came out of a really interesting conversation I had on Twitter the other day, sparked by this article on the potential complete elimination of both the National Endowment for the Humanities and the National Endowment for the Arts. During the course of the conversation, I realized that the person I was talking to (who was not a researcher, as far as I know) had some misconceptions about the role and reach of the NEH. So I thought it might be useful to talk about the role the NEH plays in my field, and has played in my own development as a researcher.

I think the easiest way to answer this is to give you specific examples of projects that have been funded by the National Endowment for the Humanities, and talk about thier individual impacts. Keep in mind that this is just the tip of the iceberg; I’m only going to talk about projects that have benefitted my work in particular, and not even all of those.
Sure, it could be. Nothing’s stopping companies from funding basic research in the humanities… but in my experience it’s not a priority, and they don’t. And that’s a real pity, because basic humanities research has a tendency of suddenly being vitally needed in other fields. Some examples from Natural Language Processing that have come up in just the last year:
These are all areas of research we’d traditionally consider humanities that have directly benefited the NLP community, and in turn many of the products and services we use day to day. But it’s hard to imagine companies supporting the work of someone working in the humanities whose work might one day benefit their products. These research programs that may not have an immediate impact but end up being incredibly important down-the-line is exactly the type of long-term investment in knowledge that the NEH supports, and that really wouldn’t happen otherwise.
“Now Rachael,” you may be saying, “your work definitely counts as STEM (science, technology, engineering and math). Why do you care so much about some humanities funding going away?”
I hope the reasons that I’ve outlined above help to make the point that humanities research has long-ranging impacts and is a good investment. NEH funding was pivotal in my development as a researcher. I would not be where I am today without early research experience on projects funded by the NEH. And as a scholar working in multiple disciplines, I see how humanities research constantly enriches work in other fields, like engineering, which tend to be considered more desirable.
One final point: the National Endowment for the Humanities is, compared to other federal funding programs, very small indeed. In 2015 the federal government spent 146 million on the NEH, which was only 2% of the 7.1 billion dollar Department of Defense research budget. In other words, if everyone in the US contributed equally to the federal budget, the NEH would cost us each less than fifty cents a year. I think that’s a fair price for all of the different on-going projects the NEH funds, don’t you?
In the light of some recent white supremacist propaganda showing up on my campus, I’ve decided to spotlight a tiny bit of the amazing work being done around the country by linguists of color. Each of the scholars below is doing interesting, important linguistics research and has a Twitter account that I personally enjoy following. If you’re on this blog, you probably will as well! I’ll give you a quick intro to their research and, if it piques your interest, you can follow them on Twitter for all the latest updates.
(BTW, if you’re wondering why I haven’t included any grad students on this list, it’s becuase we generally don’t have as well developed of a research trajectory and I want this to be a useful resource for at least a few years.)
.jpg)
Dr. Charity Hudley is professor at the College of William and Mary (Go Tribe!). Her research focuses on language variation, especially the use of varieties such as African American English, in the classroom. If you know any teachers, they might find her two books on language variation in the classroom a useful resource. She and Christine Mallinson have even released an app to go with them!
Dr. Michel DeGraff is a professor at MIT. His research is on Haitian Creole, and he’s been very active in advocating for the official recognition of Haitian Creole as a distinct language. If you’re not sure what Haitian Creole looks like, go check out his Twitter; many of his tweets are in the language! He’s also done some really cool work on using technology to teach low-resource languages.
Dr. Nelson Flores is a professor at the University of Pennsylvania. His work focuses on how we create the ideas of race and language, as well as bilingualism/multilingualism and bilingual education. I really enjoy his thought-provoking discussions of recent events on his Twitter account. He also runs a blog, which is a good resource for more in-depth discussion.
Dr. Nicole Holliday is (at the moment) Chau Mellon Postdoctoral Scholar at Pomona College. Her research focuses on language use by biracial speakers. I saw her talk on how speakers use pitch differently depending on who they’re talking to at last year’s LSA meeting and it was fantastic: I’m really looking forwards to seeing her future work! She’s also a contributor to Word., an online journal about African American English.
Dr. Rupal Patel is a professor at Northeastern University, and also the founder and CEO of VocaliD. Her research focuses on the speech of speakers with developmental disabilities, and how technology can ease communication for them. One really cool project she’s working on that you can get involved with is The Human Voicebank. This is collection of voices from all over the world that is used to make custom synthetic voices for those who need them for day-to-day communication. If you’ve got a microphone and a quiet room you can help out by recording and donating your voice.
Last, but definitely not least, is Dr. John Rickford, a professor at Stanford. If you’ve taken any linguistics courses, you’re probably already familiar with his work. He’s one of the leading scholars working on African American English and was crucial in bringing a research-based evidence to bare on the Ebonics controversy. If you’re interested, he’s also written a non-academic book on African American English that I would really highly recommend; it even won the American Book Award!
So I recently had a pretty disconcerting experience. It turns out that almost no one else has heard of a word that I thought was pretty common. And when I say “no one” I’m including dialectologists; it’s unattested in the Oxford English Dictionary and the Dictionary of American Regional English. Out of the twenty two people who responded to my Twitter poll (which was probably mostly other linguists, given my social networks) only one other person said they’d even heard the word and, as I later confirmed, it turned out to be one of my college friends.
So what is this mysterious word that has so far evaded academic inquiry? Ladies, gentlemen and all others, please allow me to introduce you to…

The word means something like “fool” or “incompetent person”. To prove that this is actually a real word that people other than me use, I’ve (very, very laboriously) found some examples from the internet. It shows up in the comments section of this news article:
THAT is why people are voting for Mr Trump, even if he does act sometimes like a Bumpus.
I also found it in a smattering of public tweets like this one:
If you ever meet my dad, please ask him what a “bumpus” is
And this one:
Having seen horror of war, one would think, John McCain would run from war. No, he runs to war, to get us involved. What a bumpus.
And, my personal favorite, this one:
because the SUN(in that pic) is wearing GLASSES god karen ur such a bumpus
There’s also an Urban Dictionary entry which suggests the definition:
A raucous, boisterous person or thing (usually african-american.)
I’m a little sceptical about the last one, though. Partly because it doesn’t line up with my own intuitions (I feel like a bumpus is more likely to be silent than rowdy) and partly becuase less popular Urban Dictionary entries, especially for words that are also names, are super unreliable.
I also wrote to my parents (Hi mom! Hi dad!) and asked them if they’d used the word growing up, in what contexts, and who they’d learned it from. My dad confirmed that he’d heard it growing up (mom hadn’t) and had a suggestion for where it might have come from:
I am pretty sure my dad used it – invariably in one of the two phrases [“don’t be a bumpus” or “don’t stand there like a bumpus”]…. Bumpass, Virginia is in Lousia County …. Growing up in Norfolk, it could have held connotations of really rural Virginia, maybe, for Dad.
While this is definitely a possibility, I don’t know that it’s definitely the origin of the word. Bumpass, Virginia, like Bumpass Hell (see this review, which also includes the phrase “Don’t be a bumpass”), was named for an early settler. Interestingly, the college friend mentioned earlier is also from the Tidewater region of Virginia, which leads me to think that the word may have originated there.
My mom offered some other possible origins, that the term might be related to “country bumpkin” or “bump on a log”. I think the latter is especially interesting, given that “bump on a log” and “bumpus” show up in exactly the same phrase: standing/sitting there like a _______.
She also suggested it might be related to “bumpkis” or “bupkis”. This is a possibility, especially since that word is definitely from Yiddish and Norfolk, VA does have a history of Jewish settlement and Yiddish speakers.
A usage of “Bumpus” which seems to be the most common is in phrases like “Bumpus dog” or “Bumpus hound”. I think that this is probably actually a different use, though, and a direct reference to a scene from the movie A Christmas Story:
One final note is that there was a baseball pitcher in the late 1890’s who went by the nickname “Bumpus”: Bumpus Jones. While I can’t find any information about where the nickname came from, this post suggests that his family was from Virginia and that he had Powhatan ancestry.
I’m really interesting in learning more about this word and its distribution. My intuition is that it’s mainly used by older, white speakers in the South, possibly centered around the Tidewater region of Virginia.
Edit, July 2020: Hello! This blog post has been cited quite a bit recently so I thought I’d update it with the more recent reserach. I’m no longer working actively on this topic, but in the last paper I wrote on it, in 2017, I found that when audio quality was controlled the gender effects disappeared. I take this to be evidence that differences in gender are due to differences in overall signal-to-noise ratio when recording in noisy environments rather than problems in the underlying ML models.
That said, bias against specific demographics categories in automatic speech recognition is a problem. In my 2017 study, I found that multiple commercial ASR systems had higher error rates for non-white speakers. More recent research has found the same effect: ASR systems make more errors for Black speakers than white speakers. In my professional opinion, the racial differences are both more important and difficult to solve.
The original, unedited blog post, continues below.
_____
In my last post, I looked at how Google’s automatic speech recognition worked with different dialects. To get this data, I hand-checked annotations more than 1500 words from fifty different accent tag videos .
Now, because I’m a sociolinguist and I know that it’s important to stratify your samples, I made sure I had an equal number of male and female speakers for each dialect. And when I compared performance on male and female talkers, I found something deeply disturbing: YouTube’s auto captions consistently performed better on male voices than female voice (t(47) = -2.7, p < 0.01.) . (You can see my data and analysis here.)
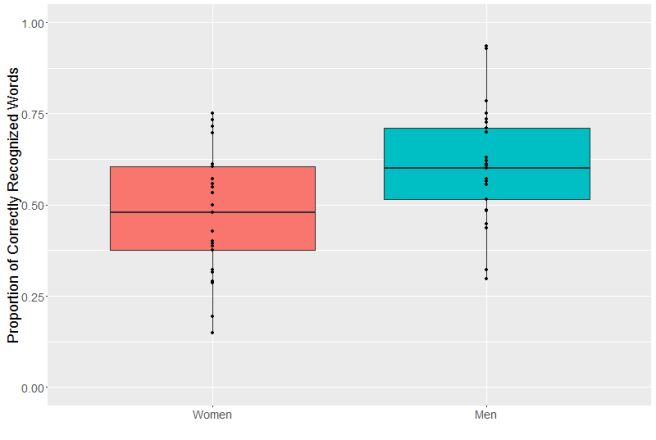
It’s not that there’s a consistent but small effect size, either, 13% is a pretty big effect. The Cohen’s d was 0.7 which means, in non-math-speak, that if you pick a random man and random woman from my sample, there’s an almost 70% chance the transcriptions will be more accurate for the man. That’s pretty striking.
What it is not, unfortunately, is shocking. There’s a long history of speech recognition technology performing better for men than women:
This is a real problem with real impacts on people’s lives. Sure, a few incorrect Youtube captions aren’t a matter of life and death. But some of these applications have a lot higher stakes. Take the medical dictation software study. The fact that men enjoy better performance than women with these technologies means that it’s harder for women to do their jobs. Even if it only takes a second to correct an error, those seconds add up over the days and weeks to a major time sink, time your male colleagues aren’t wasting messing with technology. And that’s not even touching on the safety implications of voice recognition in cars.
So where is this imbalance coming from? First, let me make one thing clear: the problem is not with how women talk. The suggestion that, for example, “women could be taught to speak louder, and direct their voices towards the microphone” is ridiculous. In fact, women use speech strategies that should make it easier for voice recognition technology to work on women’s voices. Women tend to be more intelligible (for people without high-frequency hearing loss), and to talk slightly more slowly. In general, women also favor more standard forms and make less use of stigmatized variants. Women’s vowels, in particular, lend themselves to classification: women produce longer vowels which are more distinct from each other than men’s are. (Edit 7/28/2016: I have since found two papers by Sharon Goldwater, Dan Jurafsky and Christopher D. Manning where they found better performance for women than men–due to the above factors and different rates of filler words like “um” and “uh”.) One thing that may be making a difference is that women also tend not to be as loud, partly as a function of just being smaller, and cepstrals (the fancy math thing what’s under the hood of most automatic voice recognition) are sensitive to differences in intensity. This all doesn’t mean that women’s voices are more difficult; I’ve trained classifiers on speech data from women and they worked just fine, thank you very much. What it does mean is that women’s voices are different from men’s voices, though, so a system designed around men’s voices just won’t work as well for women’s.
Which leads right into where I think this bias is coming from: unbalanced training sets. Like car crash dummies, voice recognition systems were designed for (and largely by) men. Over two thirds of the authors in the Association for Computational Linguistics Anthology Network are male, for example. Which is not to say that there aren’t truly excellent female researchers working in speech technology (Mari Ostendorf and Gina-Anne Levow here at the UW and Karen Livescu at TTI-Chicago spring immediately to mind) but they’re outnumbered. And that unbalance seems to extend to the training sets, the annotated speech that’s used to teach automatic speech recognition systems what things should sound like. Voxforge, for example, is a popular open source speech dataset that “suffers from major gender and per speaker duration imbalances.” I had to get that info from another paper, since Voxforge doesn’t have speaker demographics available on their website. And it’s not the only popular corpus that doesn’t include speaker demographics: neither does the AMI meeting corpus, nor the Numbers corpus. And when I could find the numbers, they weren’t balanced for gender. TIMIT, which is the single most popular speech corpus in the Linguistic Data Consortium, is just over 69% male. I don’t know what speech database the Google speech recognizer is trained on, but based on the speech recognition rates by gender I’m willing to bet that it’s not balanced for gender either.
Why does this matter? It matters because there are systematic differences between men’s and women’s speech. (I’m not going to touch on the speech of other genders here, since that’s a very young research area. If you’re interested, the Journal of Language and Sexuality is a good jumping-off point.) And machine learning works by making computers really good at dealing with things they’ve already seen a lot of. If they get a lot of speech from men, they’ll be really good at identifying speech from men. If they don’t get a lot of speech from women, they won’t be that good at identifying speech from women. And it looks like that’s the case. Based on my data from fifty different speakers, Google’s speech recognition (which, if you remember, is probably the best-performing proprietary automatic speech recognition system on the market) just doesn’t work as well for women as it does for men.
I’ll admit it: I used to be a die-hard grammar corrector. I practically stalked around conversations with a red pen, ready to jump out and shout “gotcha!” if someone ended a sentence with a preposition or split an infinitive or said “irregardless”. But I’ve done a lot of learning and growing since then and, looking back, I’m kind of ashamed. The truth is, when I used to correct people’s grammar, I wasn’t trying to help them. I was trying to make myself look like a language authority, but in doing so I was actually hurting people. Ironically, I only realized this after years of specialized training to become an actual authority on language.

But what do I mean when I say I was hurting people? Well, like some other types of policing, the grammar police don’t target everyone equally. For example, there has been a lot of criticism of Rihanna’s language use in her new single “Work” being thrown around recently. But that fact is that her language is perfectly fine. She’s just using Jamaican Patois, which most American English speakers aren’t familiar with. People claiming that the language use in “Work” is wrong is sort of similar to American English speakers complaining that Nederhop group ChildsPlay’s language use is wrong. It’s not wrong at all, it’s just different.
And there’s the problem. The fact is that grammar policing isn’t targeting speech errors, it’s targeting differences that are, for many people, perfectly fine. And, overwhelmingly, the people who make “errors” are marginalized in other ways. Here are some examples to show you what I mean:
In each of these cases, the “error” in question is one that’s produced more by certain groups of people. And those groups of people–less educated individuals, women, African Americans–face disadvantages in other aspects of their life too. This isn’t a mistake or coincidence. When we talk about certain ways of talking, we’re talking about certain types of people. And almost always we’re talking about people who already have the deck stacked against them.
Think about this: why don’t American English speakers point out whenever the Queen of England says things differently? For instance, she often fails to produce the “r” sound in words like “father”, which is definitely not standardized American English. But we don’t talk about how the Queen is “talking lazy” or “dropping letters” like we do about, for instance, “th” being produced as “d” in African American English. They’re both perfectly regular, logical language varieties that differ from standardized American English…but only one group gets flack for it.
Now I’m not arguing that language errors don’t exist, since they clearly do. If you’ve ever accidentally said a spoonerism or suffered from a tip of the tongue moment then you know what it feel like when your language system breaks down for a second. But here’s a fundamental truth of linguistics: barring a condition like aphasia, a native speaker of a language uses their language correctly. And I think it’s important for us all to examine exactly why it is that we’ve been led to believe otherwise…and who it is that we’re being told is wrong.


{kind=link}
{kind=link}