
Edit, July 2020: Hello! This blog post has been cited quite a bit recently so I thought I’d update it with the more recent reserach. I’m no longer working actively on this topic, but in the last paper I wrote on it, in 2017, I found that when audio quality was controlled the gender effects disappeared. I take this to be evidence that differences in gender are due to differences in overall signal-to-noise ratio when recording in noisy environments rather than problems in the underlying ML models.
That said, bias against specific demographics categories in automatic speech recognition is a problem. In my 2017 study, I found that multiple commercial ASR systems had higher error rates for non-white speakers. More recent research has found the same effect: ASR systems make more errors for Black speakers than white speakers. In my professional opinion, the racial differences are both more important and difficult to solve.
The original, unedited blog post, continues below.
_____
In my last post, I looked at how Google’s automatic speech recognition worked with different dialects. To get this data, I hand-checked annotations more than 1500 words from fifty different accent tag videos .
Now, because I’m a sociolinguist and I know that it’s important to stratify your samples, I made sure I had an equal number of male and female speakers for each dialect. And when I compared performance on male and female talkers, I found something deeply disturbing: YouTube’s auto captions consistently performed better on male voices than female voice (t(47) = -2.7, p < 0.01.) . (You can see my data and analysis here.)
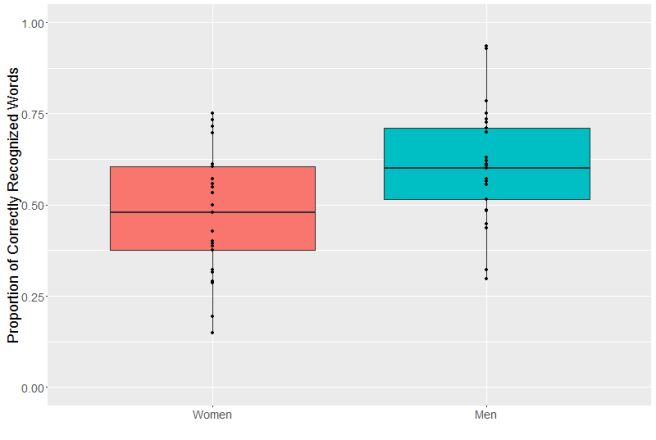
It’s not that there’s a consistent but small effect size, either, 13% is a pretty big effect. The Cohen’s d was 0.7 which means, in non-math-speak, that if you pick a random man and random woman from my sample, there’s an almost 70% chance the transcriptions will be more accurate for the man. That’s pretty striking.
What it is not, unfortunately, is shocking. There’s a long history of speech recognition technology performing better for men than women:
- It’s Not You, It’s It: Voice Recognition Doesn’t Recognize Women (Times, 2011)
- Study finding that medical voice-dictation software performs significantly better for men (Roger & Pendharkar 2003)
- Paper finding that speech recognition performs worse for women than men, and worse for girls than boys (Nicol et al. 2002)
This is a real problem with real impacts on people’s lives. Sure, a few incorrect Youtube captions aren’t a matter of life and death. But some of these applications have a lot higher stakes. Take the medical dictation software study. The fact that men enjoy better performance than women with these technologies means that it’s harder for women to do their jobs. Even if it only takes a second to correct an error, those seconds add up over the days and weeks to a major time sink, time your male colleagues aren’t wasting messing with technology. And that’s not even touching on the safety implications of voice recognition in cars.
So where is this imbalance coming from? First, let me make one thing clear: the problem is not with how women talk. The suggestion that, for example, “women could be taught to speak louder, and direct their voices towards the microphone” is ridiculous. In fact, women use speech strategies that should make it easier for voice recognition technology to work on women’s voices. Women tend to be more intelligible (for people without high-frequency hearing loss), and to talk slightly more slowly. In general, women also favor more standard forms and make less use of stigmatized variants. Women’s vowels, in particular, lend themselves to classification: women produce longer vowels which are more distinct from each other than men’s are. (Edit 7/28/2016: I have since found two papers by Sharon Goldwater, Dan Jurafsky and Christopher D. Manning where they found better performance for women than men–due to the above factors and different rates of filler words like “um” and “uh”.) One thing that may be making a difference is that women also tend not to be as loud, partly as a function of just being smaller, and cepstrals (the fancy math thing what’s under the hood of most automatic voice recognition) are sensitive to differences in intensity. This all doesn’t mean that women’s voices are more difficult; I’ve trained classifiers on speech data from women and they worked just fine, thank you very much. What it does mean is that women’s voices are different from men’s voices, though, so a system designed around men’s voices just won’t work as well for women’s.
Which leads right into where I think this bias is coming from: unbalanced training sets. Like car crash dummies, voice recognition systems were designed for (and largely by) men. Over two thirds of the authors in the Association for Computational Linguistics Anthology Network are male, for example. Which is not to say that there aren’t truly excellent female researchers working in speech technology (Mari Ostendorf and Gina-Anne Levow here at the UW and Karen Livescu at TTI-Chicago spring immediately to mind) but they’re outnumbered. And that unbalance seems to extend to the training sets, the annotated speech that’s used to teach automatic speech recognition systems what things should sound like. Voxforge, for example, is a popular open source speech dataset that “suffers from major gender and per speaker duration imbalances.” I had to get that info from another paper, since Voxforge doesn’t have speaker demographics available on their website. And it’s not the only popular corpus that doesn’t include speaker demographics: neither does the AMI meeting corpus, nor the Numbers corpus. And when I could find the numbers, they weren’t balanced for gender. TIMIT, which is the single most popular speech corpus in the Linguistic Data Consortium, is just over 69% male. I don’t know what speech database the Google speech recognizer is trained on, but based on the speech recognition rates by gender I’m willing to bet that it’s not balanced for gender either.
Why does this matter? It matters because there are systematic differences between men’s and women’s speech. (I’m not going to touch on the speech of other genders here, since that’s a very young research area. If you’re interested, the Journal of Language and Sexuality is a good jumping-off point.) And machine learning works by making computers really good at dealing with things they’ve already seen a lot of. If they get a lot of speech from men, they’ll be really good at identifying speech from men. If they don’t get a lot of speech from women, they won’t be that good at identifying speech from women. And it looks like that’s the case. Based on my data from fifty different speakers, Google’s speech recognition (which, if you remember, is probably the best-performing proprietary automatic speech recognition system on the market) just doesn’t work as well for women as it does for men.





