
If you’ve been following my blog for a while, you may remember that last year I found that YouTube’s automatic captions didn’t work as well for some dialects, or for women. The effects I found were pretty robust, but I wanted to replicate them for a couple of reasons:
- I only looked at one system, YouTube’s automatic captions, and even that was over a period of several years instead of at just one point in time. I controlled for time-of-upload in my statistical models, but it wasn’t the fairest system evaluation.
- I didn’t control for the audio quality, and since speech recognition is pretty sensitive to things like background noise and microphone quality, that could have had an effect.
- The only demographic information I had was where someone was from. Given recent results that find that natural language processing tools don’t work as well for African American English, I was especially interested in looking at automatic speech recognition (ASR) accuracy for African American English speakers.
With that in mind, I did a second analysis on both YouTube’s automatic captions and Bing’s speech API (that’s the same tech that’s inside Microsoft’s Cortana, as far as I know).
Speech Data
For this project, I used speech data from the International Dialects of English Archive. It’s a collection of English speech from all over, originally collected to help actors sound more realistic.
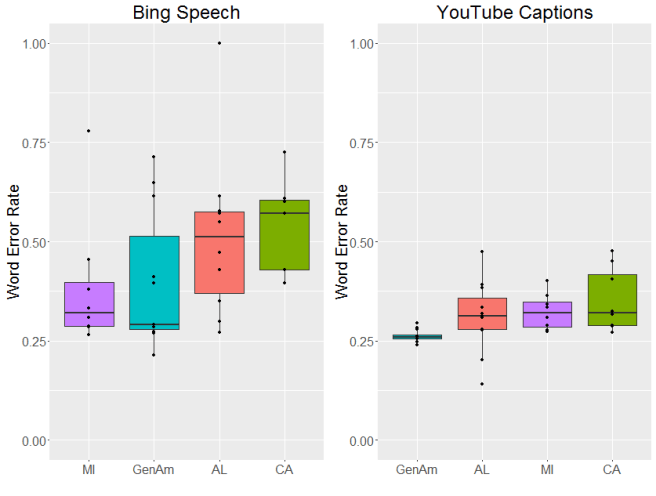
I used speech data from four varieties: the South (speakers from Alabama), the Northern Cities (Michigan), California (California) and General American. “General American” is the sort of news-caster style of speech that a lot of people consider unaccented–even though it’s just as much an accent as any of the others! You can hear a sample here.
For each variety, I did an acoustic analysis to make sure that speakers I’d selected actually did use the variety I thought they should, and they all did.
Systems
For the YouTube captions, I just uploaded the speech files to YouTube as videos and then downloaded the subtitles. (I would have used the API instead, but when I was doing this analysis there was no Python Google Speech API, even though very thorough documentation had already been released.)
Bing’s speech API was a little more complex. For this one, my co-author built a custom Android application that sent the files to the API & requested a long-form transcript back. For some reason, a lot of our sound files were returned as only partial transcriptions. My theory is that there is a running confidence function for the accuracy of the transcription, and once the overall confidence drops below a certain threshold, you get back whatever was transcribed up to there. I don’t know if that’s the case, though, since I don’t have access to their source code. Whatever the reason, the Bing transcriptions were less accurate overall than the YouTube transcriptions, even when we account for the fact that fewer words were returned.
Results
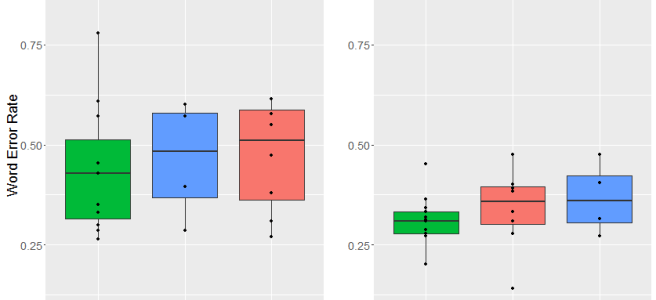
OK, now to the results. Let’s start with dialect area. As you might be able to tell from the graphs below, there were pretty big differences between the two systems we looked at. In general, there was more variation in the word error rate for Bing and overall the error rate tended to be a bit higher (although that could be due to the incomplete transcriptions we mentioned above). YouTube’s captions were generally more accurate and more consistent. That said, both systems had different error rates across dialects, with the lowest average error rates for General American English.
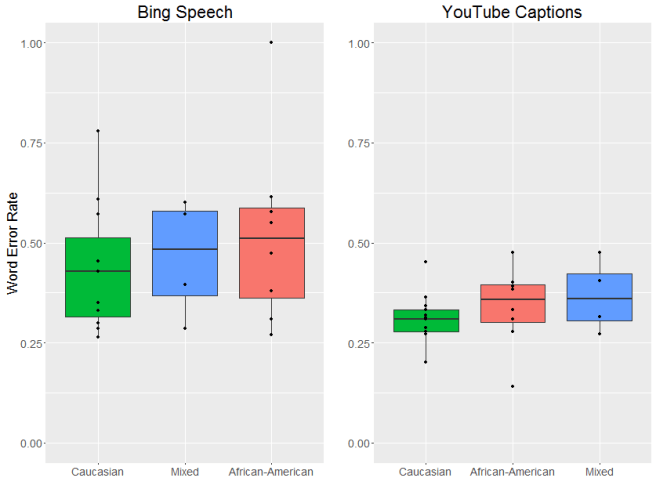
So why did I find an effect last time? My (untested) hypothesis is that there was a difference in the signal to noise ratio for male and female speakers in the user-uploaded files. Since women are (on average) smaller and thus (on average) slightly quieter when they speak, it’s possible that their speech was more easily masked by background noises, like fans or traffic. These files were all recorded in a quiet place, however, which may help to explain the lack of difference between genders.

So what? Why does word error rate matter?
There are two things I’m really worried about with these types of speech recognition errors. The first is higher error rates seem to overwhelmingly affect already-disadvantaged groups. In the US, strong regional dialects tend to be associated with speakers who aren’t as wealthy, and there is a long and continuing history of racial discrimination in the United States.
Given this, the second thing I’m worried about is the fact that these voice recognition systems are being incorporated into other applications that have a real impact on people’s lives.
- Recently, an Irish veterinarian living in Australia was denied permanent residency in Australia after failing an English fluency test based on automatic speech recognition. She was a native English speaker.
- A recent paper proposes using automatic speech recognition to automatically score a clinical test used to diagnose, among other things, speech impairment, ADHD, dementia and schizophrenia.
- Voice recognition is increasingly being incorporated into the hiring process. One example is HireVue, a software product designed to pre-screen candidates before they talk to a recruiter. A direct quote from the HireVue CEO when asked whether it might make a mistake on a candidate: “the algorithm is always right. It would be a ‘Yes’ or a ‘No.’” (Yikes!)
Every automatic speech recognition system makes errors. I don’t think that’s going to change (certainly not in my lifetime). But I do think we can get to the point where those error don’t disproportionately affect already-marginalized people. And if we keep using automatic speech recognition into high-stakes situations it’s vital that we get to that point quickly and, in the meantime, stay aware of these biases.
If you’re interested in the long version, you can check out the published paper here.





{kind=link}
{kind=link}