
Today’s blog post is a bit different. It’s in dance!
If that wasn’t quite clear enough for you, you can check this blog post for a more detailed explanation.
Today’s blog post is a bit different. It’s in dance!
If that wasn’t quite clear enough for you, you can check this blog post for a more detailed explanation.
If you’ve been following my blog for a while, you may remember that last year I found that YouTube’s automatic captions didn’t work as well for some dialects, or for women. The effects I found were pretty robust, but I wanted to replicate them for a couple of reasons:
With that in mind, I did a second analysis on both YouTube’s automatic captions and Bing’s speech API (that’s the same tech that’s inside Microsoft’s Cortana, as far as I know).
For this project, I used speech data from the International Dialects of English Archive. It’s a collection of English speech from all over, originally collected to help actors sound more realistic.
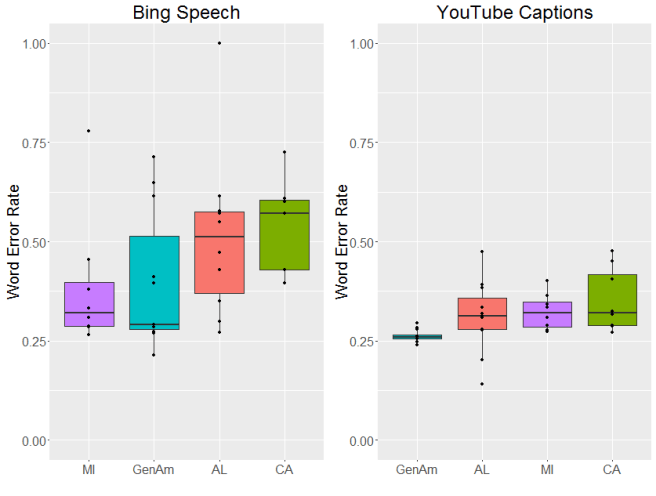
I used speech data from four varieties: the South (speakers from Alabama), the Northern Cities (Michigan), California (California) and General American. “General American” is the sort of news-caster style of speech that a lot of people consider unaccented–even though it’s just as much an accent as any of the others! You can hear a sample here.
For each variety, I did an acoustic analysis to make sure that speakers I’d selected actually did use the variety I thought they should, and they all did.
For the YouTube captions, I just uploaded the speech files to YouTube as videos and then downloaded the subtitles. (I would have used the API instead, but when I was doing this analysis there was no Python Google Speech API, even though very thorough documentation had already been released.)
Bing’s speech API was a little more complex. For this one, my co-author built a custom Android application that sent the files to the API & requested a long-form transcript back. For some reason, a lot of our sound files were returned as only partial transcriptions. My theory is that there is a running confidence function for the accuracy of the transcription, and once the overall confidence drops below a certain threshold, you get back whatever was transcribed up to there. I don’t know if that’s the case, though, since I don’t have access to their source code. Whatever the reason, the Bing transcriptions were less accurate overall than the YouTube transcriptions, even when we account for the fact that fewer words were returned.
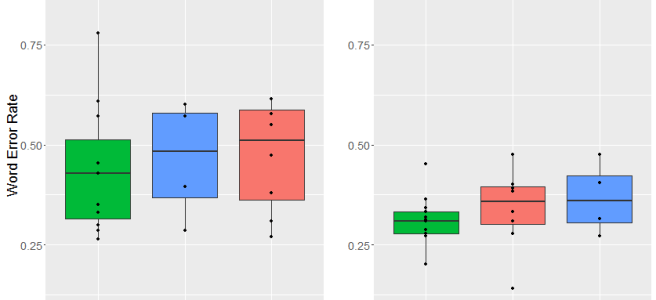
OK, now to the results. Let’s start with dialect area. As you might be able to tell from the graphs below, there were pretty big differences between the two systems we looked at. In general, there was more variation in the word error rate for Bing and overall the error rate tended to be a bit higher (although that could be due to the incomplete transcriptions we mentioned above). YouTube’s captions were generally more accurate and more consistent. That said, both systems had different error rates across dialects, with the lowest average error rates for General American English.
So why did I find an effect last time? My (untested) hypothesis is that there was a difference in the signal to noise ratio for male and female speakers in the user-uploaded files. Since women are (on average) smaller and thus (on average) slightly quieter when they speak, it’s possible that their speech was more easily masked by background noises, like fans or traffic. These files were all recorded in a quiet place, however, which may help to explain the lack of difference between genders.

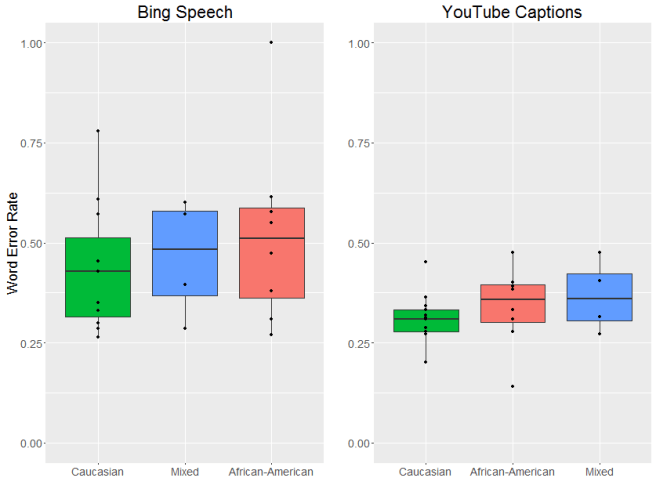
There are two things I’m really worried about with these types of speech recognition errors. The first is higher error rates seem to overwhelmingly affect already-disadvantaged groups. In the US, strong regional dialects tend to be associated with speakers who aren’t as wealthy, and there is a long and continuing history of racial discrimination in the United States.
Given this, the second thing I’m worried about is the fact that these voice recognition systems are being incorporated into other applications that have a real impact on people’s lives.
Every automatic speech recognition system makes errors. I don’t think that’s going to change (certainly not in my lifetime). But I do think we can get to the point where those error don’t disproportionately affect already-marginalized people. And if we keep using automatic speech recognition into high-stakes situations it’s vital that we get to that point quickly and, in the meantime, stay aware of these biases.
If you’re interested in the long version, you can check out the published paper here.
I’ll get back to “a male/a female” question in my next blog post (promise!), but for now I want to discuss some of the findings from my dissertation research. I’ve talked about my dissertation research a couple times before, but since I’m going to be presenting some of it in Spain (you can read the full paper here), I thought it would be a good time to share some of my findings.
In my dissertation, I’m looking at how what you think you know about a speaker affects what you hear them say. In particular, I’m looking at American English speakers who have just learned to correctly identify the vowels of New Zealand English. Due to an on-going vowel shift, the New Zealand English vowels are really confusing for an American English speaker, especially the vowels in the words “head”, “head” and “had”.

These overlaps can be pretty confusing when American English speakers are talking to New Zealand English speakers, as this Flight of the Conchords clip shows!
The good news is that, as language users, we’re really good at learning new varieties of languages we already know, so it only takes a couple minutes for an American English speaker to learn to correctly identify New Zealand English vowels. My question was this: once an American English speaker has learned to understand the vowels of New Zealand English, how do they know when to use this new understanding?
In order to test this, I taught twenty one American English speakers who hadn’t had much, if any, previous exposure to New Zealand English to correctly identify the vowels in the words “head”, “heed” and “had”. While I didn’t play them any examples of a New Zealand “hid”–the vowel in “hid” is said more quickly in addition to having different formants, so there’s more than one way it varies–I did let them say that they’d heard “hid”, which meant I could tell if they were making the kind of mistakes you’d expect given the overlap between a New Zealand “head” and American “hid”.
So far, so good: everyone quickly learned the New Zealand English vowels. To make sure that it wasn’t that they were learning to understand the one talker they’d been listening to, I tested half of my listeners on both American English and New Zealand English vowels spoken by a second, different talker. These folks I told where the talker they were listening to was from. And, sure enough, they transferred what they’d learned about New Zealand English to the new New Zealand speaker, while still correctly identifying vowels in American English.
The really interesting results here, though, are the ones that came from the second half the listeners. This group I lied to. I know, I know, it wasn’t the nicest thing to do, but it was in the name of science and I did have the approval of my institutional review board, (the group of people responsible for making sure we scientists aren’t doing anything unethical).
In an earlier experiment, I’d played only New Zealand English as this point, and when I told them the person they were listening to was from America, they’d completely changed the way they listened to those vowels: they labelled New Zealand English vowels as if they were from American English, even though they’d just learned the New Zealand English vowels. And that’s what I found this time, too. Listeners learned the New Zealand English vowels, but “undid” that learning if they thought the speaker was from the same dialect as them.
But what about when I played someone vowels from their own dialect, but told them the speaker was from somewhere else? In this situation, listeners ignored my lies. They didn’t apply the learning they’d just done. Instead, the correctly treated the vowels of thier own dialect as if they were, in fact, from thier dialect.
At first glance, this seems like something of a contradiction: I just said that listeners rely on social information about the person who’s talking, but at the same time they ignore that same social information.
So what’s going on?
I think there are two things underlying this difference. The first is the fact that vowels move. And the second is the fact that you’ve heard a heck of a lot more of your own dialect than one you’ve been listening to for fifteen minutes in a really weird training experiment.
So what do I mean when I say vowels move? Well, remember when I talked about formants above? These are areas of high acoustic energy that occur at certain frequency ranges within a vowel and they’re super important to human speech perception. But what doesn’t show up in the plot up there is that these aren’t just static across the course of the vowel–they move. You might have heard of “diphthongs” before: those are vowels where there’s a lot of formant movement over the course of the vowel.
And the way that vowels move is different between different dialects. You can see the differences in the way New Zealand and American English vowels move in the figure below. Sure, the formants are in different places—but even if you slid them around so that they overlapped, the shape of the movement would still be different.

Ok, so the vowels are moving in different ways. But why are listeners doing different things between the two dialects?
Well, remember how I said earlier that you’ve heard a lot more of your own dialect than one you’ve been trained on for maybe five minutes? My hypothesis is that, for the vowels in your own dialect, you’re highly attuned to these movements. And when a scientist (me) comes along and tells you something that goes against your huge amount of experience with these shapes, even if you do believe them, you’re so used to automatically understanding these vowels that you can’t help but correctly identify them. BUT if you’ve only heard a little bit of a new dialect you don’t have a strong idea of what these vowels should sound like, so if you’re going to rely more on the other types of information available to you–like where you’re told the speaker is from–even if that information is incorrect.
So, to answer the question I posed in the title, can what you think you know about someone affect how you hear them? Yes… but only if you’re a little uncertain about what you heard in the first place, perhaps becuase it’s a dialect you’re unfamiliar with.
So a friend of mine who’s a reference librarian (and has a gaming YouTube channel you should check out) recently got an interesting question: how loud would a million dogs barking be?

So, first off, we need to establish our baseline. The loudest recorded dog bark clocked in at 113.1 dB, and was produced by a golden retriever named Charlie. (Interestingly, the loudest recorded human scream was 129 dB, so it looks like Charlie’s got some training to do to catch up!) That’s louder than a chain saw, and loud enough to cause hearing damage if you heard it consonantly.
Now, let’s scale our problem down a bit and figure out how loud it would be if ten Charlies barked together. (I’m going to use copies of Charlie and assume they’ll bark in phase becuase it makes the math simpler.) One Charlie is 113 dB, so your first instinct may be to multiply that by ten and end up 1130 dB. Unfortunately, if you took this approach you’d be (if you’ll excuse the expression) barking up the wrong tree. Why? Because the dB scale is logarithmic. This means that a 1130 dB is absolutely ridiculously loud. For reference, under normal conditions the loudest possible sound (on Earth) is 194 dB. A sound of 1000 dB would be loud enough to create a black hole larger than the galaxy. We wouldn’t be able to get a bark that loud even if we covered every inch of earth with clones of champion barker Charlie.
Ok, so we know what one wrong approach is, but what’s the right one? Well, we have our base bark at 113 dB. If we want a bark that is one million times as powerful (assuming that we can get a million dogs to bark as one) then we need to take the base ten log of one million and multiply it by ten (that’s the deci part of decibel). (If you want more math try this site.) The base ten log of one million is six, so times ten that’s sixty decibels. But it’s sixty decibels louder than our original sound of 113dB, for a grand total of 173dB.
Now, to put this in perspective, that’s still pretty durn loud. That’s loud enough to cause hearing loss in our puppies and everyone in hearing distance. We’re talking about the loudness of a cannon, or a rocket launch from 100 meters away. So, yes, very loud, but not quite “destroying the galaxy” loud.
A final note: since the current world record for loudest barking group of dogs is a more modest 124 dB from group of just 76 dogs, if you could get a million dogs to bark in unison you’d definitely set a new world record! But, considering that you’d end up hurting the dogs’ hearing (and having to scoop all that poop) I’m afraid I really can’t recommend it.
I got a cool question from Veronica the other day:
Which wavelength someone would use not to hear but feel it on the body as a vibration?
So this would depend on two things. The first is your hearing ability. If you’ve got no or limited hearing, most of your interaction with sound will be tactile. This is one of the reasons why many Deaf individuals enjoy going to concerts; if the sound is loud enough you’ll be able to feel it even if you can’t hear it. I’ve even heard stories about folks who will take balloons to concerts to feel the vibrations better. In this case, it doesn’t really depend on the pitch of the sound (how high or low it is), just the volume.
But let’s assume that you have typical hearing. In that case, the relationship between pitch, volume and whether you can hear or feel a sound is a little more complex. This is due to something called “frequency response”. Basically, the human ear is better tuned to hearing some pitches than others. We’re really sensitive to sounds in the upper ranges of human speech (roughly 2k to 4k Hz). (The lowest pitch in the vocal signal can actually be much lower [down to around 80 Hz for a really low male voice] but it’s less important to be able to hear it because that frequency is also reflected in harmonics up through the entire pitch range of the vocal signal. Most telephones only transmit signals between 300 Hz to 3400 Hz, for example, and it’s only really the cut-off at the upper end of the range that causes problems–like making it hard to tell the difference between “sh” and “s”.)
The takeaway from all this is that we’re not super good at hearing very low sounds. That means they can be very, very loud before we pick up on them. If the sound is low enough and loud enough, then the only way we’ll be able to sense it is by feeling it.
How low is low enough? Most people can’t really hear anything much below 20 Hz (like the lowest note on a really big organ). The older you are and the more you’ve been exposed to really loud noises in that range, like bass-heavy concerts or explosions, the less you’ll be able to pick up on those really low sounds.
What about volume? My guess for what would be “sufficiently loud”, in this case, is 120+ Db. 120 Db is as loud as a rock concert, and it’s possible, although difficult and expensive, to get out of a home speaker set-up. If you have a neighbor listening to really bass-y music or watching action movies with a lot of low, booming sound effects on really expensive speakers, it’s perfectly possible that you’d feel those vibrations rather than hearing them. Especially if there are walls between the speakers and you. While mid and high frequency sounds are pretty easy to muffle, low-frequency sounds are much more difficult to sound proof against.
Are there any health risks? The effects of exposure to these types of low-frequency noise is actually something of an active research question. (You may have heard about the “brown note“, for example.) You can find a review of some of that research here. One comforting note: if you are exposed to a very loud sound below the frequencies you can easily hear–even if it’s loud enough to cause permanent damage at much higher frequencies–it’s unlikely that you will suffer any permanent hearing loss. That doesn’t mean you shouldn’t ask your neighbor to turn down the volume, though; for their ears if not for yours!
I got an interesting question on Facebook a while ago and though it might be a good topic for a blog post:
I say “good morning” to nearly everyone I see while I’m out running. But I don’t actually say “good”, do I? It’s more like “g’ morning” or “uh morning”. Never just morning by itself, and never a fully articulated good. Is there a name for this grunt that replaces a word? Is this behavior common among English speakers, only southeastern speakers, or only pre-coffee speakers?
This sort of thing is actually very common in speech, especially in conversation. (Or “in the wild” as us laboratory types like to call it.) The fancy-pants name for it is “hypoarticulation”. That’s less (hypo) speech-producing movements of the mouth and throat (articulation). On the other end of the spectrum you have “hyperarticulation” where you very. carefully. produce. each. individual. sound.
Ok, so you can change how much effort you put into producing speech sounds, fair enough. But why? Why don’t we just sort of find a happy medium and hang out there? Two reasons:
So we want to communicate clearly and unambiguously, but with as little effort as possible. But how does that tie in with this example? “G” could be “great” or “grass” or “génial “, and “uh” could be any number of things. For this we need to look outside the linguistic system.
The thing is, language is a social activity and when we’re using language we’re almost always doing so with other people. And whenever we interact with other people, we’re always trying to guess what they know. If we’re pretty sure someone can get to the word we mean with less information, for example if we’ve already said it once in the conversation, then we will expend less effort in producing the word. These contexts where things are really easily guessable are called “low entropy“. And in a social context like jogging past someone in the morning, phrases liked “good morning” have very low entropy. Much lower than, for example “Could you hand me that pickle?”–if you jogged past someone and said that you’d be very likely to hyperarticulate to make sure they understood.
Atif asked:
My neighbor talks loudly on the phone and I can’t sleep. What is the best method to block his voice noise?
Great question Atif! There are few things more distracting than hearing someone else’s conversation, and only hearing one side of a phone conversation is even worse. Even if you don’t want it to, your brain is trying to fill in the gaps and that can definitely keep you awake. So what’s the best way to avoid hearing your neighbor? Well, probably the very best way is to try talking to them. Failing that, though, you have three main options: isolation, damping and masking.

So what’s the difference between them and what’s the best option for you? Before we get down to the nitty gritty I think it’s worth a quick reminder of what sound actually is: sound waves are just that–waves. Just like waves in a lake or ocean. Imagine you and a neighbor share a small pond and you like to go swimming every morning. Your neighbor, on the other hand, has a motorboat that they drive around on thier side. The waves the motorboat makes keep hitting you as you try to swim and you want to avoid them. This is very similar to your situation: your neighbor’s voice is making waves and you want to avoid being hit by them.
Isolation: So one way to avoid feeling the effects of waves in a pond, to use our example, is to build a wall down the center of the pond. As long as there no holes in the wall for the waves to diffract through, you should be able to avoid feeling the effects of the waves. Noise isolation works much the same way. You can use earplugs that are firmly mounted in your ears to form a seal and that should prevent any sound waves from reaching your eardrums, right? Well, not quite. The wrinkle is that sound can travel through solids as well. It’s like we built our wall in our pond out of something flexible, like rubber, instead of something solid, like brick. As waves hit the wall the wall itself will move with the wave and then transmit it to your side. So you may still end up hearing some noises, even with well-fitted headphones.
Techniques: earplugs/earbuds, noise isolating headphone or earbuds, noise-isolating architecture,
Damping: So in our pond example we might imagine doing something that makes it harder for waves to move through the water. If you replaced all the water with molasses or honey, for example, it would take a lot more energy for the sound waves to move through it and they’d dissipate more quickly.
Techniques: acoustic tiles, covering the intervening wall (with a fabric wall-hanging, foam, empty egg cartons, etc.), covering vents, placing a rolled-up towel under any doors, hanging heavy curtains over windows, putting down carpeting
Masking: Another way to avoid noticing our neighbor’s waves is to start making our own waves. We can either make waves that are exactly the same size as our neighbor’s but out of phase (so when theirs are at their highest peak, ours is at our lowest) so they end up cancelling each other out. That’s basically what noise-cancelling headphones do. Or we can make a lot of own waves that all feel enough like our neighbor’s that when thier wave arrives we don’t even notice it. Of course, if the point it to hear no sound that won’t work quite as well. But if the point is to avoid abrupt, distracting changes in sound then this can work quite nicely.
Techniques: Listening to white noise or music, using noise-cancelling headphones or earbuds
So what would I do? Well, first I’d take as many steps as I could to sound-proof my environment. Try to cover as many of the surfaces in your bedroom as in absorbent, ideally fluffy, surfaces as you can. (If it can absorb water it will probably help absorb sound.) Wall hangings, curtains and a throw rug can all help a great deal.
Then you have a couple options for masking. A fan help to provide both a bit of acoustic masking and a nice breeze. Personally, though, I like a white noise machine that gives you some control over the frequency (how high or low the pitch is) and intensity (loudness) of the sounds it makes. That lets you tailor it so that it best masks the sounds that are bothering you. I also prefer the ones with the fans rather than those that loop recorded sounds, since I often find the loop jarring. If you don’t want to or can’t buy one, though, myNoise has a number of free generators that let you tailor the frequency and intensity of a variety of sounds and don’t have annoying loops. (There are a bunch of additional features available that you can access for a small donation as well.)
If you can wear earbuds in bed, try playing a non-distracting noise at around 200-1000 Hertz, which will cover a lot of the speech sounds you can’t easily dampen. Make sure your earbuds are well-fitted in the ear canal so that as much noise is isolated as possible. In addition, limiting the amount of exposed hard surface on them will also increase noise isolation. You can knit little cozies, try to find earbuds with a nice thick silicon/rubber coating or even try coating your own.
By using many different strategies together you can really reduce unwanted noises. I hope this helps and good luck!
So tomorrow is my generals exam (the title’s a bit misleading: I’m actually going to be presenting research I’ve done so my committee can decide if I’m ready to start work on my dissertation–fingers crossed!). I thought it might be interesting to discuss some of the research I’m going to be presenting in a less formal setting first, though. It’s not at the same level of general interest as the Twitter research I discussed a couple weeks ago, but it’s still kind of a cool project. (If I do say so myself.)

Basically, I wanted to know whether there are carryover effects for some of the mostly commonly-used linguistics tasks. A carryover effect is when you do something and whatever it was you were doing continues to affect you after you’re done. This comes up a lot when you want to test multiple things on the same person.
An example might help here. So let’s say you’re testing two new malaria treatments to see which one works best. You find some malaria patients, they agree to be in your study, and you give them treatment A and record thier results. Afterwards, you give them treatment B and again record their results. But if it turns out that treatment A cures Malaria (yay!) it’s going to look like treatment B isn’t doing anything, even if it is helpful, because everyone’s been cured of Malaria. So thier behavior in the second condition (treatment B) is affected by thier participation in the first condition (treatment A): the effects of treatment A have carried over.
There are a couple of ways around this. The easiest one is to split your group of participants in half and give half of them A first and half of them B first. However, a lot of times when people are using multiple linguistic tasks in the same experiment, then won’t do that. Why? Because one of the things that linguists–especially sociolinguists–want to control for is speech style. And there’s a popular idea in sociolinguistics that you can make someone talk more formally, but it’s really hard to make them talk less formally. So you tend to end up with a fixed task order going from informal tasks to more formal tasks.
So, we have two separate ideas here:
So what’s a poor linguist to do? Balance task order to prevent carryover effects but risk not getting the informal speech they’re interested in? Or keep task order fixed to get informal and formal speech but at the risk of carryover effects? Part of the problem is that, even though they’re really well-studied in other fields like psychology, sociology or medicine, carryover effects haven’t really been studied in linguistics before. As a result, we don’t know how bad they are–or aren’t!
Which is where my research comes in. I wanted to see if there were carryover effects and what they might look like. To do this, I had people come into the lab and do a memory game that involved saying the names of weird-looking things called Fribbles aloud. No, not the milkshakes, one of the little purple guys below (although I could definitely go for a milkshake right now). Then I had them do one linguistic elicitation tasks (reading a passage, doing an interview, reading a list of words or, to control for the effects of just sitting there for a bit, an arithmetic task). Then I had them repeat the Fribble game. Finally, I compared a bunch of measures from speech I recorded during the two Fribble games to see if there was any differences.

What did I find? Well, first, I found the same thing a lot of other people have found: people tend to talk while doing different things. (If I hadn’t found that, then it would be pretty good evidence that I’d done something wrong when designing my experiment.) But the really exciting thing is that I found, for some specific measures, there weren’t any carryover effects. I didn’t find any carryover effects for speech speed, loudness or any changes in pitch. So if you’re looking at those things you can safely reorder your experiments to help avoid other effects, like fatigue.
But I did find that something a little more interesting was happening with the way people were saying their vowels. I’m not 100% sure what’s going on with that yet. The Fribble names were funny made-up words (like “Kack” and “Dut”) and I’m a little worried that what I’m seeing may be a result of that weirdness… I need to do some more experiments to be sure.
Still, it’s pretty exciting to find that there are some things it looks like you don’t need to worry about carryover effects for. That means that, for those things, you can have a static order to maintain the style continuum and it doesn’t matter. Or, if you’re worried that people might change what they’re doing as they get bored or tired, you can switch the order around to avoid having that affect your data.
I’m writing this blog post from a cute little tea shop in Victoria, BC. I’m up here to present at the Northwest Linguistics Conference, which is a yearly conference for both Canadian and American linguists (yes, I know Canadians are Americans too, but United Statsian sounds weird), and I thought that my research project may be interesting to non-linguists as well. Basically, I investigated whether it’s possible for Twitter users to “type with an accent”. Can linguists use variant spellings in Twitter data to look at the same sort of sound patterns we see in different speech communities?

So if you’ve been following the Great Ideas in Linguistics series, you’ll remember that I wrote about sociolinguistic variables a while ago. If you didn’t, sociolinguistic variables are sounds, words or grammatical structures that are used by specific social groups. So, for example, in Southern American English (representing!) the sound in “I” is produced with only one sound, so it’s more like “ah”.
Now, in speech these sociolinguistic variables are very well studied. In fact, the Dictionary of American Regional English was just finished in 2013 after over fifty years of work. But in computer mediated communication–which is the fancy term for internet language–they haven’t been really well studied. In fact, some scholars suggested that it might not be possible to study speech sounds using written data. And on the surface of it, that does make sense. Why would you expect to be able to get information about speech sounds from a written medium? I mean, look at my attempt to explain an accent feature in the last paragraph. It would be far easier to get my point across using a sound file. That said, I’d noticed in my own internet usage that people were using variant spellings, like “tawk” for “talk”, and I had a hunch that they were using variant spellings in the same way they use different dialect sounds in speech.
While hunches have their place in science, they do need to be verified empirically before they can be taken seriously. And so before I submitted my abstract, let alone gave my talk, I needed to see if I was right. Were Twitter users using variant spellings in the same way that speakers use different sound patterns? And if they are, does that mean that we can investigate sound patterns using Twitter data?
Since I’m going to present my findings at a conference and am writing this blog post, you can probably deduce that I was right, and that this is indeed the case. How did I show this? Well, first I picked a really well-studied sociolinguistic variable called the low back merger. If you don’t have the merger (most African American speakers and speakers in the South don’t) then you’ll hear a strong difference between the words “cot” and “caught” or “god” and “gaud”. Or, to use the example above, you might have a difference between the words “talk” and “tock”. “Talk” is little more backed and rounded, so it sounds a little more like “tawk”, which is why it’s sometimes spelled that way. I used the Twitter public API and found a bunch of tweets that used the “aw” spelling of common words and then looked to see if there were other variant spellings in those tweets. And there were. Furthermore, the other variant spellings used in tweets also showed features of Southern American English or African American English. Just to make sure, I then looked to see if people were doing the same thing with variant spellings of sociolinguistic variables associated with Scottish English, and they were. (If you’re interested in the nitty-gritty details, my slides are here.)
Ok, so people will sometimes spell things differently on Twitter based on their spoken language dialect. What’s the big deal? Well, for linguists this is pretty exciting. There’s a lot of language data available on Twitter and my research suggests that we can use it to look at variation in sound patterns. If you’re a researcher looking at sound patterns, that’s pretty sweet: you can stay home in your jammies and use Twitter data to verify findings from your field work. But what if you’re not a language researcher? Well, if we can identify someone’s dialect features from their Tweets then we can also use those features to make a pretty good guess about their demographic information, which isn’t always available (another problem for sociolinguists working with internet data). And if, say, you’re trying to sell someone hunting rifles, then it’s pretty helpful to know that they live in a place where they aren’t illegal. It’s early days yet, and I’m nowhere near that stage, but it’s pretty exciting to think that it could happen at some point down the line.
So the big take away is that, yes, people can tweet with an accent, and yes, linguists can use Twitter data to investigate speech sounds. Not all of them–a lot of people aren’t aware of many of their dialect features and thus won’t spell them any differently–but it’s certainly an interesting area for further research.
Consonants and vowels are one of the handful of linguistics terms that have managed to escape the cage of academic discourse to make their nest in the popular conciousness. Everyone knows what the difference between a vowel and a consonant is, right? Let’s check super quick. Pick the option below that best describes a vowel:
Everyone got the second one, right? No? Huh, maybe we’re not on the same page after all.
There’s two problems with the “andsometimesY” definition of vowels. The first is that it’s based on the alphabet and, as I’ve discussed before, English has a serious problem when it comes to mapping sounds onto letters in a predictable way. (It gives you the very false impression that English has six-ish vowels when it really has twice that many.) The second is that isn’t really a good way of modelling what a vowel actually is. If we got a new letter in the alphabet tomorrow, zborp, we’d have no principled way of determining whether it was a vowel or not.

But the linguistic definition captures some other useful qualities of vowels as well. Since vowels don’t have a sharp constriction, you get acoustic energy pretty much throughout the entire spectrum. Not all frequencies are created equal, however. In vowels, the shape of the vocal tract creates pockets of more concentrated acoustic energy. We call these “formants” and they’re so stable between repetitions of vowels that they can be used to identify which vowel it is. In fact, that’s what you’re using to distinguish “beat” from “bet” from “bit” when you hear them aloud. They’re also easy to measure, which means that speech technologies rely really heavily on them.
Another quality of vowels is that, since the whole vocal tract has to unkink itself (more or less) they tend to take a while to produce. And that same openness means that not much of the energy produced at the vocal folds is absorbed. In simple terms, this means that vowels tend to be longer and louder than other sounds, i.e. consonants. This creates a neat little one-two where vowels are both easier to produce and hear. As a result, languages tend to prefer to have quite a lot of vowels, and to tack consonants on to them. This tendency shakes out create a robust pattern across languages where you’ll get one or two consonants, then a vowel, then a couple consonants, then a vowel, etc. You’ve probably run across the term linguists use for those little vowel-nuggets: we call them syllables.
If you stick with the “andsometimesY” definition, though, you lose out on including those useful qualities. It may be easier to teach to five-year-olds, but it doesn’t really capture the essential vowelyness of vowels. Fortunately, the linguistics definition does.

{kind=link}
{kind=link}