So I found a wonderful free app that lets you learn Yoruba, or at least Yoruba words, and posted about it on Google plus. Someone asked a very good question: why am I interested in Yoruba? Well, I’m not interested just in Yoruba. In fact, I would love to learn pretty much any western African language or, to be a little more precise, any Niger-Congo language.
This map’s color choices make it look like a chocolate-covered ice cream cone.Why? Well, not to put too fine a point on it, I’ve got a huge language crush on them. Whoa there, you might be thinking, you’re a linguist. You’re not supposed to make value judgments on languages. Isn’t there like a linguist code of ethics or something? Well, not really, but you are right. Linguists don’t usually make value judgments on languages. That doesn’t mean we can’t play favorites! And West African languages are my favorites. Why? Because they’re really phonologically and phonetically interesting. I find the sounds and sound systems of these languages rich and full of fascinating effects and processes. Since that’s what I study within linguistics, it makes sense that that’s a quality I really admire in a language.
What are a few examples of Niger-Congo sound systems that are just mind blowing? I’m glad you asked.
Yoruba: Yoruba has twelve vowels. Seven of them are pretty common (we have all but one in American English) but if you say four of them nasally, they’re different vowels. And if you say a nasal vowel when you’re not supposed to, it’ll change the entire meaning of a word. Plus? They don’t have a ‘p’ or an ‘n’ sound. That is crazy sauce! Those are some of the most widely-used sounds in human language. And Yoruba has a complex tone system as well. You probably have some idea of the level of complexity that can add to a sound system if you’ve ever studied Mandarin, or another East Asian language. Seriously, their sound system makes English look childishly simplistic.
Akan: There are several different dialects of Akan, so I’ll just stick to talking about Asante, which is the one used in universities and for official business. It’s got a crazy consonant system. Remember how Yoruba didn’t have an “n” sound? Yeah, in Akan they have nine. To an English speaker they all pretty much sound the same, but if you grew up speaking Akan you’d be able to tell the difference easily. Plus, most sounds other than “p”, “b”, “f” or “m” can be made while rounding the lips (linguists call this “labialized” and are completely different sounds). They’ve also got a vowel harmony system, which means you can’t have vowels later in a word that are completely different from vowels earlier in the word. Oh, yeah, and tones and a vowel nasalization distinction and some really cool tone terracing. I know, right? It’s like being a kid in a candy store.
But how did these language get so cool? Well, there’s some evidence that these languages have really robust and complex sound systems because the people speaking them never underwent large-scale migration to another Continent. (Obviously, I can’t ignore the effects of colonialism or the slave trade, but it’s still pretty robust.) Which is not to say that, say, Native American languages don’t have awesome sound systems; just just tend to be slightly smaller on average.
Now that you know how kick-ass these languages, I’m sure you’re chomping at the bit to hear some of them. Your wish is my command; here’s a song in Twi (a dialect of Akan) from one of my all-time-favorite musicians: Sarkodie. (He’s making fun of Ghanaian emigrants who forget their roots. Does it get any better than biting social commentary set to a sick beat?)
So the goal of linguistics is to find and describe the systematic ways in which humans use language. And boy howdy do we humans love using language systematically. A great example of this is internet memes.
What are internet memes? Well, let’s start with the idea of a “meme”. “Memes” were posited by Richard Dawkin in his book The Selfish Gene. He used the term to describe cultural ideas that are transmitted from individual to individual much like a virus or bacteria. The science mystique I’ve written about is a great example of a meme of this type. If you have fifteen minutes, I suggest Dan Dennett’s TED talk on the subject of memes as a much more thorough introduction.
So what about the internet part? Well, internet memes tend to be a bit narrower in their scope. Viral videos, for example, seem to be a separate category from intent memes even though they clearly fit into Dawkin’s idea of what a meme is. Generally, “internet meme” refers to a specific image and text that is associated with that image. These are generally called image macros. (For a through analysis of emerging and successful internet memes, as well as an excellent object lesson in why you shouldn’t scroll down to read the comments, I suggest Know Your Meme.) It’s the text that I’m particularly interested in here.
Memes which involve language require that it be used in a very specific way, and failure to obey these rules results in social consequences. In order to keep this post a manageable size, I’m just going to look at the use of language in the two most popular image memes, as ranked by memegenerator.net, though there is a lot more to study here. (I think a study of the differing uses of the initialisms MRW [my reaction when] and MFW [my face when] on imgur and 4chan would show some very interesting patterns in the construction of identity in the two communities. Particularly since the 4chan community is made up of anonymous individuals and the imgur community is made up of named individuals who are attempting to gain status through points. But that’s a discussion for another day…)
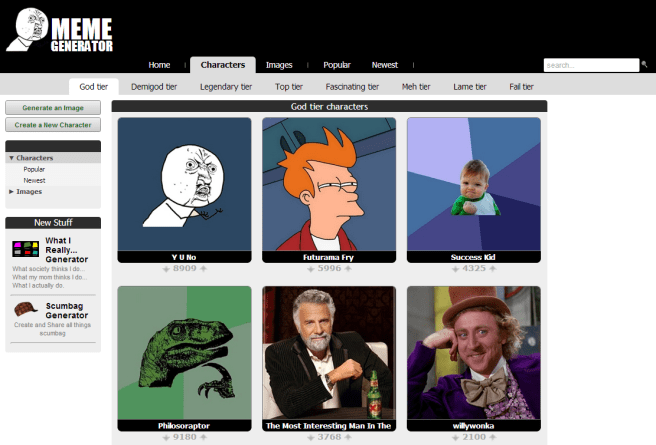
The God tier (i.e. most popular) characters at on the website Meme Generator as of February 23rd, 2013. Click for link to site. If you don’t recognize all of these characters, congratulations on not spending all your free time on the internet.
Without further ado, let’s get to the grammar. (I know y’all are excited.)
Y U No
This meme is particularly interesting because its page on Meme Generator already has a grammatical description.
The Y U No meme actually began as Y U No Guy but eventually evolved into simply Y U No, the phrase being generally followed by some often ridiculous suggestion. Originally, the face of Y U No guy was taken from Japanese cartoon Gantz’ Chapter 55: Naked King, edited, and placed on a pink wallpaper. The text for the item reads “I TXT U … Y U NO TXTBAK?!” It appeared as a Tumblr file, garnering over 10,000 likes and reblogs.
It went totally viral, and has morphed into hundreds of different forms with a similar theme. When it was uploaded to MemeGenerator in a format that was editable, it really took off. The formula used was : “(X, subject noun), [WH]Y [YO]U NO (Y, verb)?”. [Bold mine.]
A pretty good try, but it can definitely be improved upon. There are always two distinct groupings of text in this meme, always in impact font, white with a black border and in all caps. This is pretty consistent across all image macros. In order to indicate the break between the two text chunks, I will use — throughout this post. The chunk of text that appears above the image is a noun phrase that directly addresses someone or something, often a famous individual or corporation. The bottom text starts with “Y U NO” and finishes with a verb phrase. The verb phrase is an activity or action that the addressee from the first block of text could or should have done, and that the meme creator considers positive. It is also inflected as if “Y U NO” were structurally equivalent to “Why didn’t you”. So, since you would ask Steve Jobs “Why didn’t you donate more money to charity?”, a grammatical meme to that effect would be “STEVE JOBS — Y U NO DONATE MORE MONEY TO CHARITY”. In effect, this meme questions someone or thing who had the agency to do something positive why they chose not to do that thing. While this certainly has the potential to be a vehicle for social commentary, like most memes it’s mostly used for comedic effect. Finally, there is some variation in the punctuation of this meme. While no punctuation is the most common, an exclamation points, a question mark or both are all used. I would hypothesize that the the use of punctuation varies between internet communities… but I don’t really have the time or space to get into that here.
A meme (created by me using Meme Generator) following the guidelines outlined above.
Futurama Fry
This meme also has a brief grammatical analysis
The text surrounding the meme picture, as with other memes, follows a set formula. This phrasal template goes as follows: “Not sure if (insert thing)”, with the bottom line then reading “or just (other thing)”. It was first utilized in another meme entitled “I see what you did there”, where Fry is shown in two panels, with the first one with him in a wide-eyed expression of surprise, and the second one with the familiar half-lidded expression.
As an example of the phrasal template, Futurama Fry can be seen saying: “Not sure if just smart …. Or British”. Another example would be “Not sure if highbeams … or just bright headlights”. The main form of the meme seems to be with the text “Not sure if trolling or just stupid”.
This meme is particularly interesting because there seems to an extremely rigid syntactic structure. The phrase follow the form “NOT SURE IF _____ — OR _____”. The first blank can either be filled by a complete sentence or a subject complement while the second blank must be filled by a subject complement. Subject complements, also called predicates (But only by linguists; if you learned about predicates in school it’s probably something different. A subject complement is more like a predicate adjective or predicate noun.), are everything that can come after a form of the verb “to be” in a sentence. So, in a sentence like “It is raining”, “raining” is the subject complement. So, for the Futurama Fry meme, if you wanted to indicate that you were uncertain whther it was raining or sleeting, both of these forms would be correct:
NOT SURE IF IT’S RAINING — OR SLEETING
NOT SURE IF RAINING — OR SLEETING
Note that, if a complete sentence is used and abbreviation is possible, it must be abbreviated. Thus the following sentence is not a good Futurama Fry sentence:
*NOT SURE IF IT IS RAINING — OR SLEETING
This is particularly interesting because the “phrasal template” description does not include this distinction, but it is quite robust. This is a great example of how humans notice and perpetuate linguistic patterns that they aren’t necessarily aware of.
A meme (created by me using Meme Generator) following the guidelines outlined above. If you’re not sure whether it’s phonetics or phonology, may I recommend this post as a quick refresher?
So this is obviously very interesting to a linguist, since we’re really interested in extracting and distilling those patterns. But why is this useful/interesting to those of you who aren’t linguists? A couple of reasons.
I hope you find it at least a little interesting and that it helps to enrich your knowledge of your experience as a human. Our capacity for patterning is so robust that it affects almost every aspect of our existence and yet it’s easy to forget that, to let our awareness of that slip our of our conscious minds. Some patterns deserve to be examined and criticized, though, and linguistics provides an excellent low-risk training ground for that kind of analysis.
If you are involved in internet communities I hope you can use this new knowledge to avoid the social consequences of violating meme grammars. These consequences can range from a gentle reprimand to mockery and scorn The gatekeepers of internet culture are many, vigilant and vicious.
As with much linguistic inquiry, accurately noting and describing these patterns is the first step towards being able to use them in a useful way. I can think of many uses, for example, of a program that did large-scale sentiment analyses of image macros but was able to determine which were grammatical (and therefore more likely to be accepted and propagated by internet communities) and which were not.
One of the more interesting little sub-fields in linguistics is diachronic semantics. That’s the study of how word meanings change over time. Some of these changes are relatively easy to track. A “mouse” to a farmer in 1900 was a small rodent with unfortunate grain-pilfering proclivities. To a farmer today, it’s also one of the tools she uses to interact with her computer. The word has gained a new semantic sense without losing it’s original meaning. Sometimes, however, you have a weird little dance where a couple of words are negotiating over the same semantic space–that’s another way of saying a related group of concepts that a language groups together–and that’s where things get interesting. “Cup”, “mug” and “glass” are engaged in that little dance-off right now (at least in American English). Let’s see how they’re doing, shall we?
Cup? Glass? Jug? Mug? Why don’t we just call them all “drinking vessels” and be done with it?Cup: Ok, quick question for you: does a cup have to have a handle? The Oxford dictionaries say “yes“, but I really think that’s out of date at this point. Dr. Reed pointed out that this was part of her criteria for whether something could be called a “cup” or not, but that a lot of younger speakers no longer make that distinction. In fact, recently I noticed that someone of my acquaintance uses “cup” to refer only to disposable cups. Cup also has the distinct advantage of being part of a lot of phrases: World cup, Stanley cup, cup of coffee, teacup, cuppa, cup of sugar, in your cups, and others that I can’t think of right now.
So “cup” is doing really well, and gaining semantic ground.
Glass: Glass, on the other hand, isn’t doing as well. I haven’t yet talked to someone who can use “glass” to refer to drinking vessels that aren’t actually made of glass including, perhaps a little oddly, clear disposable cups. On the other hand, there are some types of drinking vessels that I can only refer to as glasses. Mainly those for specific types of alcohol: wine glass, shot glass, martini glass, highball glass (though I’ve heard people referring to the glass itself just as a highball, so this might be on the way out). There are alcohol-specific pieces of glassware that don’t count as glasses though–e.g. champagne flute, brandy snifter–so it’s not a categorical distinction by any means.
“Glass” seems to be pretty stable, but if “cup” continues to become broader and broader it might find itself on the outs.
Mug: I don’t have as much observational data on this one, but there seems to be another shift going on here. “Mug” originally referred only to drinking vessels that were larger than cups (see below), and still had handles.
Note that the smaller ones on top are “cups” and the larger ones on the bottom are labelled as “mugs”.Most people call those insulated drinking vessels with the attached lids “travel mugs” rather than “travel cups” (640,000 Google hits vs. 22,400) but I find myself calling them “cups” instead. I think it’s because 1) I pattern it with disposable coffee cups and 2) I find handledness is a necessary quality for mugs. I can call all of the drinking vessels in the picture above “mugs” and prefer “mug” to “cup”.
So, at least for me, “mug” is beginning to take over the semantic space allotted to “cup” by older speakers.
Of course, this is a very cursory, impressionistic snapshot of the current state of the semantic space. Without more robust data I’m hesitant to make concrete predictions about the ways in which these terms are negotiating their semantic space, but there’s definitely some sort of drift going on.
Short answer: they’re all correct (at least in the United States) but some are more common in certain dialectal areas. Here’s a handy-dandy map, in case you were wondering:
Maps! Language! Still one of my favorite combinations. This particular map, and the data collection it’s based on is courtesy of popvssoda.com. Click picture for link and all the lovely statistics. (You do like statistics, right?)
Long answer: I’m going to sort this into reactions I tend to get after answering questions like this one.
What do you mean they’re all correct? Coke/Soda/Pop is clearly wrong. Ok, I’ll admit, there are certain situations when you might need to choose to use one over the other. Say, if you’re writing for a newspaper with a very strict style guide. But otherwise, I’m sticking by my guns here: they’re all correct. How do I know? Because each of them in is current usage, and there is a dialectal group where it is the preferred term. Linguistics (at least the type of linguistics that studies dialectal variation) is all about describing what people actually say and people actually say all three.
But why doesn’t everyone just say the same thing? Wouldn’t that be easier? Easier to understand? Probably, yes. But people use different words for the same thing for the same reasons that they speak different languages. In a very, very simplified way, it kinda works like this:
You tend to speak like the people that you spend time with. That makes it easier for you to understand each other and lets other people in your social group know that you’re all members of the same group. Like team jerseys.
Over time, your group will introduce or adopt new linguistic makers that aren’t necessarily used by the whole population. Maybe a person you know refers to sodas as “phosphates” because his grandfather was a sodajerk and that form really catches on among your friends.
As your group keeps using and adopting new words (or sounds, or grammatical markers or any other facet of language) that are different from other groups their language slowly begins to drift away from the language used by other groups.
Eventually, in extreme cases, you end up with separate languages. (Like what happened with Latin: different speech communities ended up speaking French, Italian, Spanish, Portuguese, and the other Romance languages rather than the Latin they’d shared under Roman rule.)
This is the process by which languages or dialectal communities tend to diverge. Divergence isn’t the only pressure on speakers, however. Particularly since we can now talk to and listen to people from basically anywhere (Yay internet! Yay TV! Yay radio!) your speech community could look like mine does: split between people from the Pacific Northwest and the South. My personal language use is slowly drifting from mostly Southern to a mix of Southern and Pacific Northwestern. This is called dialect leveling and it’s part of the reason why American dialectal regions tend include hundreds or thousands of miles instead of two or three.
Dialect leveling: Where two or more groups of people start out talking differently and end up talking alike. Schools tend to be a huge factor in this.
So, on the one hand, there is pressure to start all talking alike. On the other hand, however, I still want to sound like I belong with my Southern friends and have them understand me easily (and not be made fun of for sounding strange, let’s be honest) so when I’m talking to them I don’t retain very many markers of the Pacific Northwest. That’s pressure that’s keeping the dialect areas separate and the reason why I still say “soda”, even though I live in a “pop” region.
This is a problem that’s plagued me for quite a while. I’m not a computational linguist myself, but one of the reasons that theoretical linguistics is important is that it allows us to create robust concpetional models of language… which is basically what voice recognition (or synthesis) programs are. But, you may say to yourself, if it’s your job to create and test robust models, you’re clearly not doing very well. I mean, just listen to this guy. Or this guy. Or this person, whose patience in detailing errors borders on obsession. Or, heck, this person, who isn’t so sure that voice recognition is even a thing we need.
You mean you wouldn’t want to be able to have pleasant little chats with your computer? I mean, how could that possibly go wrong?Now, to be fair to linguists, we’ve kinda been out of the loop for a while. Fred Jelinek, a very famous researcher in speech recognition, once said “Every time we fire a phonetician/linguist, the performance of our system goes up”. Oof, right in the career prospects. There was, however, a very good reason for that, and it had to do with the pressures on computer scientists and linguists respectively. (Also a bunch of historical stuff that we’re not going to get into.)
Basically, in the past (and currently to a certain extent) there was this divide in linguistics. Linguists wanted to model speaker’s competence, not their performance. Basically, there’s this idea that there is some sort of place in your brain where you knew all the rules of language and have them all perfectly mapped out and described. Not in a consious way, but there nonetheless. But somewhere between the magical garden of language and your mouth and/or ears you trip up and mistakes happen. You say a word wrong or mishear it or switch bits around… all sorts of things can go wrong. Plus, of course, even if we don’t make a recognizable mistake, there’s a incredible amount of variation that we can decipher without a problem. That got pushed over to the performance side, though, and wasn’t looked at as much. Linguistics was all about what was happening in the language mind-garden (the competence) and not the messy sorts of things you say in everyday life (the performance). You can also think of it like what celebrities actually say in an interview vs. what gets into the newspaper; all the “um”s and “uh”s are taken out, little stutters or repetitions are erased and if the sentence structure came out a little wonky the reporter pats it back into shape. It was pretty clear what they meant to say, after all.
So you’ve got linguists with their competence models explaining them to the computer folks and computer folks being all clever and mathy and coming up with algorithms that seem to accurately model our knowledge of human linguistic competency… and getting terrible results. Everyone’s working hard and doing their best and it’s just not working.
I think you can probably figure out why: if you’re a computer and just sitting there with very little knowledge of language (consider that this was before any of the big corpora were published, so there wasn’t a whole lot of raw data) and someone hands you a model that’s supposed to handle only perfect data and also actual speech data, which even under ideal conditions is far from perfect, you’re going to spit out spaghetti and call it a day. It’s a bit like telling someone to make you a peanut butter and jelly sandwich and just expecting them to do it. Which is fine if they already knowwhat peanut butter and jelly are, and where you keep the bread, and how to open jars, and that food is something humans eat, so you shouldn’t rub it on anything too covered with bacteria or they’ll get sick and die. Probably not the best way to go about it.
So the linguists got the boot and they and the computational people pretty much did their own things for a bit. The model that most speech recognition programs use today is mostly statistical, based on things like how often a word shows up in whichever corpus they’re using currently. Which works pretty well. In a quiet room. When you speak clearly. And slowly. And don’t use any super-exotic words. And aren’t having a conversation. And have trained the system on your voice. And have enough processing power in whatever device you’re using. And don’t get all wild and crazy with your intonation. See the problem?
Language is incredibly complex and speech recognition technology, particularly when it’s based on a purely statistical model, is not terrific at dealing with all that complexity. Which is not to say that I’m knocking statistical models! Statistical phonology is mind-blowing and I think we in linguistics will get a lot of mileage from it. But there’s a difference. We’re not looking to conserve processing power: we’re looking to model what humans are actually doing. There’s been a shift away from the competency/performance divide (though it does still exist) and more interest in modelling the messy stuff that we actually see: conversational speech, connected speech, variation within speakers. And the models that we come up with are complex. Really complex. People working in Exemplar Theory, for example, have found quite a bit of evidence that you remember everything you’ve ever heard and use all of it to help parse incoming signals. Yeah, it’s crazy. And it’s not something that our current computers can do. Which is fine; it give linguists time to further refine our models. When computers are ready, we will be too, and in the meantime computer people and linguistic people are showing more and more overlap again, and using each other’s work more and more. And, you know, singing Kumbayah and roasting marshmallows together. It’s pretty friendly.
So what’s the take-away? Well, at least for the moment, in order to get speech recognition to a better place than it is now, we need to build models that work for a system that is less complex than the human brain. Linguistics research, particularly into statistical models, is helping with this. For the future? We need to build systems that are as complex at the human brain. (Bonus: we’ll finally be able to test models of child language acquisition without doing deeply unethical things! Not that we would do deeply unethical things.) Overall, I’m very optimistic that computers will eventually be able to recognize speech as well as humans can.
TL;DR version:
Speech recognition has been light on linguists because they weren’t modeling what was useful for computational tasks.
Now linguists are building and testing useful models. Yay!
Language is super complex and treating it like it’s not will get you hit in the face with an error-ridden fish.
Linguists know language is complex and are working diligently at accurately describing how and why. Yay!
In order to get perfect speech recognition down, we’re going to need to have computers that are similar to our brains.
Or, as I like to call it, hunting the wild Eth and Thorn (which are old letters that can be difficult to typesest), because back in the day, English had the two distinct “th” sounds represented differently in their writing system. There was one where you vibrated your vocal folds (that’s called ‘voiced’) which was written as “ð” and one where you didn’t (unvoiced) which was written as “þ”. It’s a bit like the difference between “s” and “z” in English today. Try it: you can say both “s” and “z” without moving your tongue a millimeter. Unfortunately, while the voiced and voiceless “th” sounds remain distinct, they’re now represented by the same “th” sequence. The difference between “thy” and “thigh”, for example, is the first sound, but the spelling doesn’t reflect that. (Yet another example of why English orthography is horrible.)
Used with permission from the How To Be British Collection copyright LGP, click picture for website.
The fact that they’re written with the same letters even though they’re different sounds is only part of why they’re so hard to master. (That goes for native English speakers as well as those who are learning it as their second language: it’s one of the last sounds children learn.). The other part is that they’re relatively rare across languages. Standard Arabic Greek, some varieties of Spanish, Welsh and a smattering of other languages have them. If you happen to have a native language that doesn’ t have it, though, it’s tough to hear and harder to say. Don’t worry, though, linguistics can help!
I’m afraid the cartoon above may accurately express the difficulty of producing the “th” for non-native speakers of English, but the technique is somewhat questionable. So, the fancy technical term for the “th” sounds are the interdental fricatives. Why? Because there are two parts to making it. The first is the place of articulation, which means where you put your tongue. In this case, as you can probably guess (“inter-” between and “-dental” teeth), it goes in between your teeth. Gently!
The important thing about your tongue placement is that your tongue tip needs to be pressed lightly against the bottom of your top teeth. You need to create a small space to push air thorough, small enough that it makes a hissing sound as it escapes. That’s the “fricative” part. Fricatives are sounds where you force air through a small space and the air molecules start jostling each other and make a high-frequency hissing noise. Now, it won’t be as loud when you’re forcing air between your upper teeth and tongue as it is, for example, when you’re making an “s”, but it should still be noticeable.
So, to review, put the tip of your tongue against the bottom of your top teeth. Blow air through the thin space between your tongue and your teeth so that it creates a (not very loud) hissing sound. Now try voicing the sound (vibrating your vocal folds) as you do so. That’s it! You’ve got both of the English “th” sounds down.
If you’d like some more help, I really like this video, and it has some super-cool slow-motion videos. The lady who made it has a website focusing on English pronunciation which has some great resources. Good luck!
What really got to me, though, was that after I’d finished my talk (and it was super fast, too, only five minutes) someone asked why it mattered. Why should we care that our intuitions don’t match reality? We can still communicate perfectly well. How is linguistics useful, they asked. Why should they care?
I’m sorry, what was it you plan to spend your life studying again? I know you told me last week, but for some reason all I remember you saying is “Blah, blah, giant waste of time.”
It was a good question, and I’m really bummed I didn’t have time to answer it. I sometimes forget, as I’m wading through a hip-deep piles of readings that I need to get to, that it’s not immediately obvious to other people why what I do is important. And it is! If I didn’t believe that, I wouldn’t be in grad school. (It’s certainly not the glamorous easy living and fat salary that keep me here.) It’s important in two main ways. Way one is the way in which it enhances our knowledge and way two is the way that it helps people.
Increasing our knowledge. Ok, so, a lot of our intuitions are wrong. So what? So a lot of things! If we’re perceiving things that aren’t really there, or not perceivingthings that are really there, something weird and interesting is going on. We’re really used to thinking of ourselves as pretty unbiased in our observations. Sure, we can’t hear all the sounds that are made, but we’ve built sensors for that, right? But it’s even more pervasive than that. We only perceive the things that our bodies and sensory organs and brains can perceive, and we really don’t know how all these biological filters work. Well, okay, we do know some things (lots and lots of things about ears, in particular) but there’s a whole lot that we still have left to learn. The list of unanswered questions in linguistics is a little daunting, even just in the sub-sub-field of perceptual phonetics.
Every single one of us uses language every single day. And we know embarrassingly little about how it works. And, what we do know, it’s often hard to share with people who have little background in linguistics. Even here, in my blog, without time restraints and an audience that’s already pretty interested (You guys are awesome!) I often have to gloss over interesting things. Not because I don’t think you’ll understand them, but because I’d metaphorically have to grow a tree, chop it down and spends hours carving it just to make a little step stool so you can get the high-level concept off the shelf and, seriously, who has time for that? Sometimes I really envy scientists in the major disciplines because everyone already knows the basics of what they study. Imagine that you’re a geneticist, but before you can tell people you look at DNA, you have to convince them that sexual reproduction exists. I dream of the day when every graduating high school senior will know IPA. (That’s the international phonetic alphabet, not the beer.)
Okay, off the soapbox.
Helpingpeople. Linguistics has lots and lots and lots of applications. (I’m just going to talk about my little sub-field here, so know that there’s a lot of stuff being left unsaid.) The biggest problem is that so few people know that linguistics is a thing. We can and want to help!
Foreign language teaching. (AKA applied linguistics) This one is a particular pet peeve of mine. How many of you have taken a foreign language class and had the instructor tell you something about a sound in the language, like: “It’s between a “k” and a “g” but more like the “k” except different.” That crap is not helpful. Particularly if the instructor is a native speaker of the language, they’ll often just keep telling you that you’re doing it wrong without offering a concrete way to make it correctly. Fun fact: There is an entire field dedicated to accurately describing the sounds of the world’s languages. One good class on phonetics and suddenly you have a concrete description of what you’re supposed to be doing with your mouth and the tools to tell when you’re doing it wrong. On the plus side, a lot language teachers are starting to incorporate linguistics into their curriculum with good results.
Speech recognition and speech synthesis. So this is an area that’s a little more difficult. Most people working on these sorts of projects right now are computational people and not linguists. There is a growing community of people who do both (UW offers a masters degree in computational linguistics that feeds lots of smart people into Seattle companies like Microsoft and Amazon, for example) but there’s definite room for improvement. The main tension is the fact that using linguistic models instead of statistical ones (though somelinguistic modelsare statistical) hugely increases the need for processing power. The benefit is that accuracy tends to increase. I hope that, as processing power continues to be easier and cheaper to access, more linguistics research will be incorporated into these applications. Fun fact: In computer speech recognition, an 80% comprehension accuracy rate in conversational speech is considered acceptable. In humans, that’s grounds to test for hearing or brain damage.
Speech pathology. This is a great field and has made and continues to make extensive use of linguistic research. Speech pathologists help people with speech disorders overcome them, and the majority of speech pathologists have an undergraduate degree in linguistics and a masters in speech pathology. Plus, it’s a fast-growing career field with a good outlook. Seriously, speech pathology is awesome. Fun fact: Almost half of all speech pathologists work in school environments, helping kids with speech disorders. That’s like the antithesis of a mad scientist, right there.
And that’s why you should care. Linguistics helps us learn about ourselves and help people, and what else could you ask for in a scientific discipline? (Okay, maybe explosions and mutant sharks, but do those things really help humanity?)
So for some reason, I’ve come across three studies in quick succession based in mapping language. Now, if you know me, you know that nattering on about linguistic methodology is pretty much the Persian cat to my Blofeld, but I really do think that looking at the way that linguists do linguistics is incredibly important. (Warning: the next paragraph will be kinda preachy, feel free to skip it.)
It’s something the field, to paint with an incredibly broad brush, tends to skimp on. After all, we’re asking all these really interesting questions that have the potential to change people’s lives. How is hearing speech different from hearing other things? What causes language pathologies and how can we help correct them? Can we use the voice signal to reliably detect Parkinson’s over the phone? That’s what linguistics is. Who has time to look at whether asking people to list the date on a survey form affects their responses? If linguists don’t use good, controlled methods to attempt to look at these questions, though, we’ll either find the wrong answers or miss it completely because of some confounding variable we didn’t think about. Believe me, I know firsthand how heart wrenching it is to design an experiment, run subjects, do your stats and end up with a big pile of useless goo because your methodology wasn’t well thought out. It sucks. And it happens way more than it needs to, mainly because a lot of linguistics programs don’t stress rigorous scientific training.
OK, sermon over. Maps! I think using maps to look at language data is a great methodology! Why?
Hmm… needs more data about language. Also the rest of the continents, but who am I to judge?
You get an end product that’s tangible and easy to read and use. People know what maps are and how to use them. Presenting linguistic data as a map rather than, say, a terabyte of detailed surveys or a thousand hours of recordings is a great way to make that same data accessible. Accessible data gets used. And isn’t that kind of the whole point?
Maps are so. accurate. right now. This means that maps of data aren’t just rough approximations, they’re the best, most accurate way to display this information. Seriously, the stuff you can do with GIS is just mind blowing. (Check out this dialect map of the US. If you click on the region you’re most interested, you get additional data like field recordings, along with the precise place they were made. Super useful.)
Maps are fun. Oh, come on, who doesn’t like looking at maps? Particularly if you’re looking at a region you’re familiar with. See, here’s my high school, and the hay field we rented three years ago. Oh, and there’s my friend’s house! I didn’t realize they were so close to the highway. Add a second layer of information and BOOM, instant learning.
The studies
Two of the studies I came across were actually based on Twitter data. Twitter’s an amazing resource for studying linguistics because you have this enormous data set you can just use without having to get consent forms from every single person. So nice. Plus, because all tweets are archived, in the Library of Congress if nowhere else, other researchers can go back and verify things really easily.
This study looks at how novel slang expressions spread across the US. It hasn’t actually been published yet, so I don’t have the map itself, but they do talk about some interesting tidbits. For example: the places most likely to spawn new successful slang are urban centers with a high African American population.
The second Twitter study is based in London and looked at the different languages Londoners tweet in and did have a map:
Click for link to author’s blog post.
Interesting, huh? You can really get a good idea of the linguistic landscape of London. Although there were some potential methodological problems with this study, I still think it’s a great way to present this data.
The third study I came across is one that’s actually here at the University of Washington. This one is interesting because it kind of goes the other way. Basically, the researchers has respondents indicate areas on a map of Washington where they thought language communities existed and then had them describe them. So what you end up with is sort of a representation of the social ideas of what language is like in various parts of Washington state. Like so:
Click for link to study site.
There are lots more interesting maps on the study site, each of which shows some different perception of language use in Washington State. (My favorite is the one that suggests that people think other people who live right next to the Canadian border sound Canadian.)
So these are just a couple of the ways in which people are using maps to look at language data. I hope it’s a trend that continues.
[Trigger warning: I’m going to write “shit” about a billion more times in this blog post because it is necessary to describe this linguistic observation. YOU HAVE BEEN WARNED.]
So every once in a while I notice something semantic about English that just blows my mind. I was making tea this morning and thinking about whether or not your could say that “That dress is bespoke as shit”. Why? Because I’m a linguist, but also because someone brought this cartoon to my attention again recently:
So, in the field of semantics sitting around thinking about your intuitions about words is actually pretty solid methodology, so I’m going to do that. (I know, right? Not a single ultrasound or tracheal puncture? What do they do on Saturday nights?) Let’s compare the following sentences:
That dress is bespoke as shit.
His wardrobe is bespoke as shit.
That dress is pink as shit.
His wardrobe is pink as shit.
My intuition is that that two and three are fine, four is… okay but a little weird and that one is downright wrong. And I also feel very strongly that the goodness of a given sentence where some quality of an object is modified by “as shit” is closely tied to whether or not that quality is a continuous scale. (And, no, I’m not going to say “adjective” here. Mainly because you can also say “Her wardrobe is completely made out of sharks as shit.” And, in my universe, at least, “completely made out of sharks” doesn’t really count as an adjective.) Things that are on a continuous scale are like darkness. It can be a little dark or really dark or completely dark; there’s not really any point where you switch from being dark to light, right? And something that’s dark for me, like a starry night, might be light for a bat. “Pink”, and all colors, are continuous scales. (FUN FACT: how many color terms various languages have and why is a really big debate.) But things like “free” (as in costing zero dollars) are more discrete. Something’s either free or it’s not and there’s not really any middle ground.
The other thing you need to take into account is whether or not the thing being described is plural and whether it’s a mass or count noun. Mass nouns are things like “water”, “sand” or “bubblegum”. You can less or more or some of these things, but you can’t count them. “I’ll have three water” just sounds really odd. Count nouns are things like “buckets of water”, “grains of sand” or “pieces of bubblegum”. These are things that have discrete, countable units instead of just a lump of mass. It’s a really useful distinction.
Ok, so how does this gel with my intuitions? And, more importantly, can I describe qualities in such a way that my description has predictive power? (Remember, linguistics is all about building testable models of language use!) I think I can. Let’s roll up our sleeves and get to the knitty-gritty. I’ve got two separate parts of the sentence that go into whether or not I can use “as shit”: the thing(s) being described, and the quality it has. The thing being described can be either singular or plural, and either mass or count. The quality it has can either be continuous or discrete. Let’s put this in outline form to make the possible different conditions a bit easier to see:
Thing being described
Is it singular? If yes, is it:
A mass noun? If so, assign condition 1.
A count noun? If so, assign condition 2.
Is it plural? If yes, is it:
A mass noun? If so, assign condition TRICK QUESTION, because that’s not possible. 😛
Is it a count noun? If so, assign condition 3.
Qualities: continuous or discrete
Is it continuous? If so, assign condition A
Is it discrete? If so, assign condition B.
[What’s that, pseudocode? I thought you didn’t do “computer-y code-y math-y things”, Rachael.] Ok, so now we’ve got six possible conditions for a given sentence (1A, 2A, 3A, 1B, 2B and 3B). Which conditions can take “as shit” and why? (Keep in mind, this is just my intuition.
1A: “Water is big as shit.” = acceptable
2A: “The dog is big as shit.” = acceptable
3A: “The dogs are big as shit.” = acceptable
1B: “Water is still as shit.” = unacceptable
2B “The dog is still as shit.” = unacceptable
3B: “The dogs are still as shit.” = acceptable
Okay, so a little of my reasoning. I feel very strong that “as shit” serves to intensify the adjective and you can’t intensify something that’s binary. The light switch it either on or off; it’s can’t be extremely on or extremely off. So all of the B conditions are bad… except for 3B. What is 3B acceptable? Well, for me what I get the sense that what you’re saying is not that you’re intensifying the qualities of each individual but that you’re talking about the group as whole. And if you add up a bunch of binaries (three still dogs and one moving dog) you can get value somewhere in the middle.
But that’s just a really informal little model based on my intuitions and I feel like they’re getting screwed up because I’ve spent way too much time thinking about this. And now the tea that I was making is getting cold as shit, so I might as well go drink it.
A lot of us, as literate English speakers, have probably experienced that queasy moment of dread when you’re writing something on the computer and suddenly get a squiggly red line under a word you use all the time. You look at the suggested spellings… and none of them are the word you wanted. If you’re like me, at this point you hop online really quickly to make sure the word means what you thought it did and that you’re not butchering the spelling too horribly. Or maybe you turn to the dictionary you keep on your desk. Or maybe you turn to someone sitting next to you and ask “Is this a real word?”.
Oh, this? It’s just the pocket edition. The full one is three hundred volumes and comes with an elephant named George to carry it around your house. And it’s covered in gold. This edition is only bound in unicorn skin but it’s fine for a quick desk reference.The underlying assumption behind the search to see if someone else uses the word is that, if they don’t, you can’t either. It’s not a “real word”. Which begs the question: what makes a word real? Is there a moment of Pinocchio-like transformation where the hollow wooden word someone created suddenly takes on life and joins the ranks of the English language to much back-slapping and cigar-handing from the other vetted words? Is there a little graduation party where the word gets a diploma from the OED and suddenly it’s okay to use it whenever you want? Or does it get hired by the spelling board and get to work right away?
OK, so that was getting a bit silly, but my point is that most people have the vague notion that there’s a distinction between “real” words and “fake” words that’s pretty hard and fast. Like most slang words and brand names are fake words. I like to call this the Scrabble distinction. If you can play it in Scrabble, it counts and you can put it in a paper or e-mail and no one will call you on it. If you can’t, it’s a fake word and you use it at your own risk. Dictionaries play a large part in determining which is which, right? The official Scrabble dictionary is pretty conservative: it doesn’t have d’oh in it for example. But it’s also not without controversy. The first official Scrabble dictionary, for example, didn’t have “granola” in it, which the Oxford English Dictionary (the great grand-daddy of English dictionaries and probably the most complete record ever complied of the lexicon of any language ever) notes was first used in 1886 and I think most of us would agree is a “real” word.
The line is even blurrier than that, though. English is a language with a long and rich written tradition. In some ways, that’s great. We’ve got a lot more information on how words used to be pronounced than we would have otherwise and a lot of diachronic information. (That’s information about how the language has changed over time. 😛 ) But if you’ve been exposed mainly to the English tradition, as I have, you tend to forget that writing isn’t inseparable from spoken language. They’re two different things and there are a lot of traditions that aren’t writing-based. Consider, for example, the Odù Ifá, an entirely oral divination text from Nigeria that sometimes gets compared to the bible or the Qur’an. In the cultures I was raised in, the thought of a sacred text that you can’t read is strange, but that’s just part of the cultural lens that Isee the world through; I shouldn’t project that bias onto other cultures.
So non-literary cultures still need to add words to their lexicons, right? But how do they know which words are “real” without dictionaries? It depends. Sometimes it just sort of happens organically. We see this in English too. Think about words associated with texting or IMing like “lol” or “brb” (that’s “laughing out loud” and “be right back” for those of you who are still living under rocks). I’ve noticed people saying these in oral conversations more and more and I wouldn’t be surprised if in fifty years “burb” started showing up in dictionaries. But even cultures which have only had writing systems for a very short amounts of time have gatekeepers. Navajo, which has only been written since around 1940, is a great example. Peter Ladefoged shares the following story in Phonetic Data Analysis:
One of our former UCLA linguistics students who is a Navajo tells how she was once giving a talk in a Navajo community. She was showing how words could be put together to create new words (such as sweet + heart creates a word with an entirely new meaning). When she was explaining this an elder called out: ‘Stop this blasphemy! Only the gods can create words.’ The Navajo language is holy in a way that is very foreign to most of us (p. 13).
So in Navajo you have elders and religious leaders who are the guardians of the language and serve as the final authorities. (FUN FACT: “authority” comes from the same root as “author”. See how writing-dependent English is?) There are always gray areas though. Language is, after all, incredibly complex. I’ll leave you one case to think about.
“Rammaflagit.” That’s ɹæm.ə.flæʒ.ɪt in the international phonetic alphabet. (I remember how thrilled my dad was when I told him I was studying IPA in college.) I hear it all the time and it means something like “gosh darn it”, sort of a bolderized curse word. Real word or not? The dictionaries say “no”, but the people who I’ve heard using it would clearly say “yes”. What do you think?