So I recently had a pretty disconcerting experience. It turns out that almost no one else has heard of a word that I thought was pretty common. And when I say “no one” I’m including dialectologists; it’s unattested in the Oxford English Dictionary and the Dictionary of American Regional English. Out of the twenty two people who responded to my Twitter poll (which was probably mostly other linguists, given my social networks) only one other person said they’d even heard the word and, as I later confirmed, it turned out to be one of my college friends.
So what is this mysterious word that has so far evaded academic inquiry? Ladies, gentlemen and all others, please allow me to introduce you to…
Pronounced ‘bʌm.pɪs or ‘bʌm.pəs. You can hear me say the word and use it in context by listening to this low quality recording.
The word means something like “fool” or “incompetent person”. To prove that this is actually a real word that people other than me use, I’ve (very, very laboriously) found some examples from the internet. It shows up in the comments section of this news article:
THAT is why people are voting for Mr Trump, even if he does act sometimes like a Bumpus.
I also found it in a smattering of public tweets like this one:
If you ever meet my dad, please ask him what a “bumpus” is
A raucous, boisterous person or thing (usually african-american.)
I’m a little sceptical about the last one, though. Partly because it doesn’t line up with my own intuitions (I feel like a bumpus is more likely to be silent than rowdy) and partly becuase less popular Urban Dictionary entries, especially for words that are also names, are super unreliable.
I also wrote to my parents (Hi mom! Hi dad!) and asked them if they’d used the word growing up, in what contexts, and who they’d learned it from. My dad confirmed that he’d heard it growing up (mom hadn’t) and had a suggestion for where it might have come from:
I am pretty sure my dad used it – invariably in one of the two phrases [“don’t be a bumpus” or “don’t stand there like a bumpus”]…. Bumpass, Virginia is in Lousia County …. Growing up in Norfolk, it could have held connotations of really rural Virginia, maybe, for Dad.
While this is definitely a possibility, I don’t know that it’s definitely the origin of the word. Bumpass, Virginia, like Bumpass Hell (see this review, which also includes the phrase “Don’t be a bumpass”), was named for an early settler. Interestingly, the college friend mentioned earlier is also from the Tidewater region of Virginia, which leads me to think that the word may have originated there.
My mom offered some other possible origins, that the term might be related to “country bumpkin” or “bump on a log”. I think the latter is especially interesting, given that “bump on a log” and “bumpus” show up in exactly the same phrase: standing/sitting there like a _______.
She also suggested it might be related to “bumpkis” or “bupkis”. This is a possibility, especially since that word is definitely from Yiddish and Norfolk, VA does have a history of Jewish settlement and Yiddish speakers.
A usage of “Bumpus” which seems to be the most common is in phrases like “Bumpus dog” or “Bumpus hound”. I think that this is probably actually a different use, though, and a direct reference to a scene from the movie A Christmas Story:
One final note is that there was a baseball pitcher in the late 1890’s who went by the nickname “Bumpus”: Bumpus Jones. While I can’t find any information about where the nickname came from, this post suggests that his family was from Virginia and that he had Powhatan ancestry.
I’m really interesting in learning more about this word and its distribution. My intuition is that it’s mainly used by older, white speakers in the South, possibly centered around the Tidewater region of Virginia.
If you’ve heard of or used this word, please leave a comment or drop me a line letting me know 1) roughly how old you are, 2) where you grew up and 3) (if you can remember) where you learned it. Feel free to add any other information you feel might be relevant, too!
The most frustrating homophone triplet in English is there, their and they’re, which are all said [ðɛr]. They’re a pain, and one that I’ve found that even really smart adults struggle with. And, frankly, I think a lot of that has to do with the fact that they’re not usually taught in a very linguistically sophisticated way. Luckily for y’all, “linguistic sophistication” is my middle name*. And, like all good linguists I’ve got some tests to help you figure out which [ðɛr] you need.
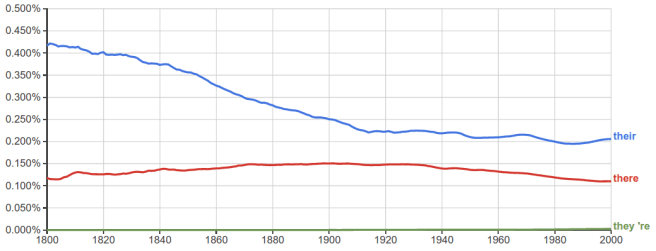
If tests aren’t your style and you just want to play the odds, though, guess “their”, “there” and “they’re” in that order. According to Google’s n-gram viewer (click the chart to go play around with it) “their” is the most common [ðɛr] in writing, followed by “there” and then “they’re”.
There. So the confusing thing here is that there are really *two* there’s in English and they play really different roles.
Pleonastic there. So in English we really need subjects, even when we don’t. Some sentences like “It’s raining” and “There’s no more ice-cream” don’t actually need a subject to convey what we’re getting at. There’s no thing, “it”, up in the sky that is doing the raining like there’s a person throwing a ball in “They threw the ball”. We just stick it up in there to fill out our sentence.
Test: Can you replace [ðɛr] with “it”? If so, it’s probably “there”.
Test: If the sentence has “[ðɛr] was/were/is/are/will” it will almost always be “there”.
Locative there. So “locative” is just a fancy word for “relating to a place”. Are you talking about a place? If so, then you probably need “there”.
Test: Is [ðɛr] referring to a place? If so, it’s probably “there”.
Their. So people tend to use a semantic definition for this one; does it belong to someone? It’s way easier to figure it out with part of speech, though. “Their” is part of a pretty small class of words called “determiners”– you may also have heard “articles”. One good way to test if a word belongs to the same part of speech as another is to replace it in the sentence. You know “snake” and “pudding” are both nouns because you say either “My snake fell off the shelf” or “My pudding fell off the shelf”. So all you have to do is swap it out with one of the other English Determiners and see if it works.
Test: Can you replace [ðɛr] with words like “my”, “our”, “the” or “some”? If so, it’s “their”.
They’re. This is probably the easiest one. They’re is a contraction of “they” and “are”. If you can uncontract them and the sentence still works, you’re golden.
Test: Can you replace [ðɛr] with “they are”? If so, it’s probably “they’re”.
Try out these tests next time you’re not sure which [ðɛr] is the right one and you should figure it out pretty quickly. Of course, there are some marginal cases (like when you’re talking about the words themselves) that may throw you off, but these guidelines should pull you through 99% of the time.
Today’s Great Idea in Linguistics comes to use from syntax. One interesting difference between syntax and other fields of linguistics is what is considered compelling evidence for a theory in syntax. The aim of transformational syntax is to produce a set of rules (originally phrase structure rules) that will let you produce all the grammatical sentences in a language and none of the ungrammatical ones. So, if you’re proposing a new rule you need to show that the sentences it outputs are grammatical… but how do you do that?
I sentence you to ten hours of community service for ungrammatical utterances!
One way to test whether something is grammatical is to see whether someone’s said it before. Back in the day, before you had things like large searchable corpora–or, heck even the internet–this was difficult, so say the least. Especially since the really interesting syntactic phenomena tend to be pretty rare. Lots of sentences have a subject and an object, but a lot fewer have things like wh-islands.
Another way is to see if someone will say it. This is a methodology that is often used in sociolinguistics research. The linguist interviews someone using questions that are specifically designed to elicit certain linguistic forms, like certain words or sounds. However, this methodology is chancy at best. Often times the person won’t produce whatever it is you’re looking for. Also it can be very hard to make questions or prompts to access very rare forms.
Another way to see whether something is grammatical is to see whether someone would say it. This is the type of evidence that has, historically, been used most often in syntax research. The concept is straightforward. You present a speaker of a language with a possible sentence and they use thier intuition as a native speaker to determine whether it’s good (“grammatical”) or not (“ungrammatical”). These sentences are often outputs of a proposed structure and used to argue either for or against it.
However, in practice grammaticality judgements can occasionally be a bit more difficult. Think about the following sentences:
I ate the carrot yesterday.
This sounds pretty good to me. I’d say it’s “grammatical”.
*I did ate the carrot yesterday.
I put a star (*) in front of this sentence because it sounds bad to me, and I don’t think anyone would say it. I’d say it’s “ungrammatical”.
? I done ate the carrot yesterday.
This one is a little more borderline. It’s actually something I might say, but only in a very informal context and I realize that not everyone would say it.
So if you were a syntactician working on these sentences, you’d have to decide whether your model should account for the last sentence or not. One way to get around this is by building probability into the syntactic structure. So I’m more likely to use a structure that produces the first example but there’s a small probability I might use the structure in the third example. To know what those probabilities are, however, you need to figure out how likely people are to use each of the competing structures (and whether there are other factors at play, like dialect) and for that you need either lots and lots of grammaticality judgements. It’s a new use of a traditional tool that’s helping to expand our understanding of language.
One of the great things about being human is our ability to figure patterns and then apply them in new situations. In fact, that pretty much describes the vast bulk of scientific inquiry– someone notices a thing, notices other things like it, figures that they must be motivated by some underlying process and then tries to figure it out. From gravity to DNA to the fact that maybe DDT wasn’t such a panacea after all, all important scientific discoveries have sprung from that same general process of recognizing patterns.
And that process is at work in language as well. Let’s take a look at the following way of conjugating English verbs.
I walk We walk
You walk You walk
He/she/it walks They walk
Now, if you’re the noticing type of person you might find that there’ s a glaring problem that’s messing up an otherwise nice, predictable pattern: that odd out-of-place “s” in “She walks.” Why, it’s downright irksome. Wouldn’t it make a lot more sense just to get rid of it entirely and have a nice, lovely, completely predictable conjugation like this one:
I walk We walk
You walk You walk
He/she/it walk They walk
Of course it would. And in fact, there are some speakers of English who do just that. Dropping the third person singular “s”, as it turns out, is a common feature of African American English. And if similar processes in other languages, such as Latin, are any guide, we may all one day adopt this entirely sensible practice, which is commonly referred to as “paradigm levelling”.
In fact, English has already undergone a massive process of morphological simplification, including a lot of paradigm levelling, once before. During the transition from Old English to Middle English, we lost a whole bucketful of cases and person markings. This was partly due to language contact in the Danelaw, where Viking settlers interacted and intermarried with the local English-speaking population. Being no-nonsense second language learners, they did away with a lot of the odder patterns and left us with something that much more closely resembled the comparatively morphologically streamlined English of today.
And the same process has occurred over and over again the world’s languages. People notice that something isn’t what you’d expect, given the pattern in place, and choose to follow the pattern rather than historical precedent, tidying away some of the messiness that inevitably creeps into languages over time. Paradigm levelling is a powerful force for linguistic change and a useful theoretical tool in historical linguistics.
So the good folks over at Userdesign asked me to review their newest volume, Punctuation..? and I was happy to oblige. Linguists rarely study punctuation (it falls under the sub-field orthography, or the study of writing systems) but what we do study is the way that language attitudes and punctuation come together. I’ve written before about language attitudes when it come to grammar instruction and the strong prescriptive attitudes of most grammar instruction books. What makes this book so interesting is that it is partly prescriptive and partly descriptive. Since a descriptive bent in a grammar instruction manual is rare, I thought I’d delve into that a bit.
Image copyright Userdesign, used with permission. (Click for link to site.)
So, first of all, how about a quick review of the difference between a descriptive and prescriptive approach to language?
Descriptive: This is what linguists do. We don’t make value or moral judgments about languages or language use, we just say what’s going on as best we can. You can think of it like an anthropological ethnography: we just describe what’s going on.
Prescriptive: This is what people who write letters to the Times do. They have a very clear idea of what’s “right” and “wrong” with regards to language use and are all to happy to tell you about it. You can think of this like a manner book: it tells you what the author thinks you should be doing.
As a linguist, my relationship with language is mainly scientific, so I have a clear preference for a descriptive stance. An ichthyologist doesn’t tell octopi, “No, no, no, you’re doing it all wrong!” after all. At the same time, I live in a culture which has very rigid expectations for how an educated individual should write and sound, and if I want to be seen as an educated individual (and be considered for the types of jobs only open to educated individuals) you better believe I’m going to adhere to those societal standards. The problem comes when people have a purely prescriptive idea of what grammar is and what it should be. That can lead to nasty things like linguistic discrimination. I.e., language B (and thus all those individuals who speak language B) is clearly inferior to language A because they don’t do things properly. Since I think we can all agree that unfounded discrimination of this type is bad, you can see why linguists try their hardest to avoid value judgments of languages.
As I mentioned before, this book is a fascinating mix of prescriptive and descriptive snippets. For example, the author says this about exclamation points: “In everyday writing, the exclamation mark is often overused in the belief that it adds drama and excitement. It is, perhaps the punctuation mark that should be used with the most restraint” (p 19). Did you notice that “should'”? Classic marker of a prescriptivist claiming their territory. But then you have this about Guillements: “Guillements are used in several languages to indicate passages of speech in the same way that single and double quotation marks (” “”) are used in the English language” (p. 22). (Guillements look like this, since I know you were wondering; « and ». ) See, that’s a classical description of what a language does, along with parallels drawn to another, related, languages. It may not seem like much, but try to find a comparably descriptive stance in pretty much any widely-distributed grammar manual. And if you do, let me know so that I can go buy a copy of it. It’s change, and it’s positive change, and I’m a fan of it. Is this an indication of a sea-change in grammar manuals? I don’t know, but I certainly hope so.
Over all, I found this book fascinating (though not, perhaps, for the reasons the author intended!). Particularly because it seems to stand in contrast to the division that I just spent this whole post building up. It’s always interesting to see the ways that stances towards language can bleed and melt together, for all that linguists (and I include myself here) try to show that there’s a nice, neat dividing line between the evil, scheming prescriptivists and the descriptivists in their shining armor here to bring a veneer of scientific detachment to our relationship with language. Those attitudes can and do co-exist. Data is messy. Language is complex. Simple stories (no matter how pretty we might think them) are suspicious. But these distinctions can be useful, and I’m willing to stand by the descriptivist/prescriptivist, even if it’s harder than you might think to put people in one camp or the others.
But beyond being an interesting study in language attitdues, it was a fun read. I learned lots of neat little factoids, which is always a source of pure joy for me. (Did you know that this symbol: ¶ is called a Pilcrow? I know right? I had no idea either; I always just called it the paragraph mark.)
So the goal of linguistics is to find and describe the systematic ways in which humans use language. And boy howdy do we humans love using language systematically. A great example of this is internet memes.
What are internet memes? Well, let’s start with the idea of a “meme”. “Memes” were posited by Richard Dawkin in his book The Selfish Gene. He used the term to describe cultural ideas that are transmitted from individual to individual much like a virus or bacteria. The science mystique I’ve written about is a great example of a meme of this type. If you have fifteen minutes, I suggest Dan Dennett’s TED talk on the subject of memes as a much more thorough introduction.
So what about the internet part? Well, internet memes tend to be a bit narrower in their scope. Viral videos, for example, seem to be a separate category from intent memes even though they clearly fit into Dawkin’s idea of what a meme is. Generally, “internet meme” refers to a specific image and text that is associated with that image. These are generally called image macros. (For a through analysis of emerging and successful internet memes, as well as an excellent object lesson in why you shouldn’t scroll down to read the comments, I suggest Know Your Meme.) It’s the text that I’m particularly interested in here.
Memes which involve language require that it be used in a very specific way, and failure to obey these rules results in social consequences. In order to keep this post a manageable size, I’m just going to look at the use of language in the two most popular image memes, as ranked by memegenerator.net, though there is a lot more to study here. (I think a study of the differing uses of the initialisms MRW [my reaction when] and MFW [my face when] on imgur and 4chan would show some very interesting patterns in the construction of identity in the two communities. Particularly since the 4chan community is made up of anonymous individuals and the imgur community is made up of named individuals who are attempting to gain status through points. But that’s a discussion for another day…)
The God tier (i.e. most popular) characters at on the website Meme Generator as of February 23rd, 2013. Click for link to site. If you don’t recognize all of these characters, congratulations on not spending all your free time on the internet.
Without further ado, let’s get to the grammar. (I know y’all are excited.)
Y U No
This meme is particularly interesting because its page on Meme Generator already has a grammatical description.
The Y U No meme actually began as Y U No Guy but eventually evolved into simply Y U No, the phrase being generally followed by some often ridiculous suggestion. Originally, the face of Y U No guy was taken from Japanese cartoon Gantz’ Chapter 55: Naked King, edited, and placed on a pink wallpaper. The text for the item reads “I TXT U … Y U NO TXTBAK?!” It appeared as a Tumblr file, garnering over 10,000 likes and reblogs.
It went totally viral, and has morphed into hundreds of different forms with a similar theme. When it was uploaded to MemeGenerator in a format that was editable, it really took off. The formula used was : “(X, subject noun), [WH]Y [YO]U NO (Y, verb)?”. [Bold mine.]
A pretty good try, but it can definitely be improved upon. There are always two distinct groupings of text in this meme, always in impact font, white with a black border and in all caps. This is pretty consistent across all image macros. In order to indicate the break between the two text chunks, I will use — throughout this post. The chunk of text that appears above the image is a noun phrase that directly addresses someone or something, often a famous individual or corporation. The bottom text starts with “Y U NO” and finishes with a verb phrase. The verb phrase is an activity or action that the addressee from the first block of text could or should have done, and that the meme creator considers positive. It is also inflected as if “Y U NO” were structurally equivalent to “Why didn’t you”. So, since you would ask Steve Jobs “Why didn’t you donate more money to charity?”, a grammatical meme to that effect would be “STEVE JOBS — Y U NO DONATE MORE MONEY TO CHARITY”. In effect, this meme questions someone or thing who had the agency to do something positive why they chose not to do that thing. While this certainly has the potential to be a vehicle for social commentary, like most memes it’s mostly used for comedic effect. Finally, there is some variation in the punctuation of this meme. While no punctuation is the most common, an exclamation points, a question mark or both are all used. I would hypothesize that the the use of punctuation varies between internet communities… but I don’t really have the time or space to get into that here.
A meme (created by me using Meme Generator) following the guidelines outlined above.
Futurama Fry
This meme also has a brief grammatical analysis
The text surrounding the meme picture, as with other memes, follows a set formula. This phrasal template goes as follows: “Not sure if (insert thing)”, with the bottom line then reading “or just (other thing)”. It was first utilized in another meme entitled “I see what you did there”, where Fry is shown in two panels, with the first one with him in a wide-eyed expression of surprise, and the second one with the familiar half-lidded expression.
As an example of the phrasal template, Futurama Fry can be seen saying: “Not sure if just smart …. Or British”. Another example would be “Not sure if highbeams … or just bright headlights”. The main form of the meme seems to be with the text “Not sure if trolling or just stupid”.
This meme is particularly interesting because there seems to an extremely rigid syntactic structure. The phrase follow the form “NOT SURE IF _____ — OR _____”. The first blank can either be filled by a complete sentence or a subject complement while the second blank must be filled by a subject complement. Subject complements, also called predicates (But only by linguists; if you learned about predicates in school it’s probably something different. A subject complement is more like a predicate adjective or predicate noun.), are everything that can come after a form of the verb “to be” in a sentence. So, in a sentence like “It is raining”, “raining” is the subject complement. So, for the Futurama Fry meme, if you wanted to indicate that you were uncertain whther it was raining or sleeting, both of these forms would be correct:
NOT SURE IF IT’S RAINING — OR SLEETING
NOT SURE IF RAINING — OR SLEETING
Note that, if a complete sentence is used and abbreviation is possible, it must be abbreviated. Thus the following sentence is not a good Futurama Fry sentence:
*NOT SURE IF IT IS RAINING — OR SLEETING
This is particularly interesting because the “phrasal template” description does not include this distinction, but it is quite robust. This is a great example of how humans notice and perpetuate linguistic patterns that they aren’t necessarily aware of.
A meme (created by me using Meme Generator) following the guidelines outlined above. If you’re not sure whether it’s phonetics or phonology, may I recommend this post as a quick refresher?
So this is obviously very interesting to a linguist, since we’re really interested in extracting and distilling those patterns. But why is this useful/interesting to those of you who aren’t linguists? A couple of reasons.
I hope you find it at least a little interesting and that it helps to enrich your knowledge of your experience as a human. Our capacity for patterning is so robust that it affects almost every aspect of our existence and yet it’s easy to forget that, to let our awareness of that slip our of our conscious minds. Some patterns deserve to be examined and criticized, though, and linguistics provides an excellent low-risk training ground for that kind of analysis.
If you are involved in internet communities I hope you can use this new knowledge to avoid the social consequences of violating meme grammars. These consequences can range from a gentle reprimand to mockery and scorn The gatekeepers of internet culture are many, vigilant and vicious.
As with much linguistic inquiry, accurately noting and describing these patterns is the first step towards being able to use them in a useful way. I can think of many uses, for example, of a program that did large-scale sentiment analyses of image macros but was able to determine which were grammatical (and therefore more likely to be accepted and propagated by internet communities) and which were not.
One of the more interesting little sub-fields in linguistics is diachronic semantics. That’s the study of how word meanings change over time. Some of these changes are relatively easy to track. A “mouse” to a farmer in 1900 was a small rodent with unfortunate grain-pilfering proclivities. To a farmer today, it’s also one of the tools she uses to interact with her computer. The word has gained a new semantic sense without losing it’s original meaning. Sometimes, however, you have a weird little dance where a couple of words are negotiating over the same semantic space–that’s another way of saying a related group of concepts that a language groups together–and that’s where things get interesting. “Cup”, “mug” and “glass” are engaged in that little dance-off right now (at least in American English). Let’s see how they’re doing, shall we?
Cup? Glass? Jug? Mug? Why don’t we just call them all “drinking vessels” and be done with it?Cup: Ok, quick question for you: does a cup have to have a handle? The Oxford dictionaries say “yes“, but I really think that’s out of date at this point. Dr. Reed pointed out that this was part of her criteria for whether something could be called a “cup” or not, but that a lot of younger speakers no longer make that distinction. In fact, recently I noticed that someone of my acquaintance uses “cup” to refer only to disposable cups. Cup also has the distinct advantage of being part of a lot of phrases: World cup, Stanley cup, cup of coffee, teacup, cuppa, cup of sugar, in your cups, and others that I can’t think of right now.
So “cup” is doing really well, and gaining semantic ground.
Glass: Glass, on the other hand, isn’t doing as well. I haven’t yet talked to someone who can use “glass” to refer to drinking vessels that aren’t actually made of glass including, perhaps a little oddly, clear disposable cups. On the other hand, there are some types of drinking vessels that I can only refer to as glasses. Mainly those for specific types of alcohol: wine glass, shot glass, martini glass, highball glass (though I’ve heard people referring to the glass itself just as a highball, so this might be on the way out). There are alcohol-specific pieces of glassware that don’t count as glasses though–e.g. champagne flute, brandy snifter–so it’s not a categorical distinction by any means.
“Glass” seems to be pretty stable, but if “cup” continues to become broader and broader it might find itself on the outs.
Mug: I don’t have as much observational data on this one, but there seems to be another shift going on here. “Mug” originally referred only to drinking vessels that were larger than cups (see below), and still had handles.
Note that the smaller ones on top are “cups” and the larger ones on the bottom are labelled as “mugs”.Most people call those insulated drinking vessels with the attached lids “travel mugs” rather than “travel cups” (640,000 Google hits vs. 22,400) but I find myself calling them “cups” instead. I think it’s because 1) I pattern it with disposable coffee cups and 2) I find handledness is a necessary quality for mugs. I can call all of the drinking vessels in the picture above “mugs” and prefer “mug” to “cup”.
So, at least for me, “mug” is beginning to take over the semantic space allotted to “cup” by older speakers.
Of course, this is a very cursory, impressionistic snapshot of the current state of the semantic space. Without more robust data I’m hesitant to make concrete predictions about the ways in which these terms are negotiating their semantic space, but there’s definitely some sort of drift going on.
Short answer: they’re all correct (at least in the United States) but some are more common in certain dialectal areas. Here’s a handy-dandy map, in case you were wondering:
Maps! Language! Still one of my favorite combinations. This particular map, and the data collection it’s based on is courtesy of popvssoda.com. Click picture for link and all the lovely statistics. (You do like statistics, right?)
Long answer: I’m going to sort this into reactions I tend to get after answering questions like this one.
What do you mean they’re all correct? Coke/Soda/Pop is clearly wrong. Ok, I’ll admit, there are certain situations when you might need to choose to use one over the other. Say, if you’re writing for a newspaper with a very strict style guide. But otherwise, I’m sticking by my guns here: they’re all correct. How do I know? Because each of them in is current usage, and there is a dialectal group where it is the preferred term. Linguistics (at least the type of linguistics that studies dialectal variation) is all about describing what people actually say and people actually say all three.
But why doesn’t everyone just say the same thing? Wouldn’t that be easier? Easier to understand? Probably, yes. But people use different words for the same thing for the same reasons that they speak different languages. In a very, very simplified way, it kinda works like this:
You tend to speak like the people that you spend time with. That makes it easier for you to understand each other and lets other people in your social group know that you’re all members of the same group. Like team jerseys.
Over time, your group will introduce or adopt new linguistic makers that aren’t necessarily used by the whole population. Maybe a person you know refers to sodas as “phosphates” because his grandfather was a sodajerk and that form really catches on among your friends.
As your group keeps using and adopting new words (or sounds, or grammatical markers or any other facet of language) that are different from other groups their language slowly begins to drift away from the language used by other groups.
Eventually, in extreme cases, you end up with separate languages. (Like what happened with Latin: different speech communities ended up speaking French, Italian, Spanish, Portuguese, and the other Romance languages rather than the Latin they’d shared under Roman rule.)
This is the process by which languages or dialectal communities tend to diverge. Divergence isn’t the only pressure on speakers, however. Particularly since we can now talk to and listen to people from basically anywhere (Yay internet! Yay TV! Yay radio!) your speech community could look like mine does: split between people from the Pacific Northwest and the South. My personal language use is slowly drifting from mostly Southern to a mix of Southern and Pacific Northwestern. This is called dialect leveling and it’s part of the reason why American dialectal regions tend include hundreds or thousands of miles instead of two or three.
Dialect leveling: Where two or more groups of people start out talking differently and end up talking alike. Schools tend to be a huge factor in this.
So, on the one hand, there is pressure to start all talking alike. On the other hand, however, I still want to sound like I belong with my Southern friends and have them understand me easily (and not be made fun of for sounding strange, let’s be honest) so when I’m talking to them I don’t retain very many markers of the Pacific Northwest. That’s pressure that’s keeping the dialect areas separate and the reason why I still say “soda”, even though I live in a “pop” region.
Or, as I like to call it, hunting the wild Eth and Thorn (which are old letters that can be difficult to typesest), because back in the day, English had the two distinct “th” sounds represented differently in their writing system. There was one where you vibrated your vocal folds (that’s called ‘voiced’) which was written as “ð” and one where you didn’t (unvoiced) which was written as “þ”. It’s a bit like the difference between “s” and “z” in English today. Try it: you can say both “s” and “z” without moving your tongue a millimeter. Unfortunately, while the voiced and voiceless “th” sounds remain distinct, they’re now represented by the same “th” sequence. The difference between “thy” and “thigh”, for example, is the first sound, but the spelling doesn’t reflect that. (Yet another example of why English orthography is horrible.)
Used with permission from the How To Be British Collection copyright LGP, click picture for website.
The fact that they’re written with the same letters even though they’re different sounds is only part of why they’re so hard to master. (That goes for native English speakers as well as those who are learning it as their second language: it’s one of the last sounds children learn.). The other part is that they’re relatively rare across languages. Standard Arabic Greek, some varieties of Spanish, Welsh and a smattering of other languages have them. If you happen to have a native language that doesn’ t have it, though, it’s tough to hear and harder to say. Don’t worry, though, linguistics can help!
I’m afraid the cartoon above may accurately express the difficulty of producing the “th” for non-native speakers of English, but the technique is somewhat questionable. So, the fancy technical term for the “th” sounds are the interdental fricatives. Why? Because there are two parts to making it. The first is the place of articulation, which means where you put your tongue. In this case, as you can probably guess (“inter-” between and “-dental” teeth), it goes in between your teeth. Gently!
The important thing about your tongue placement is that your tongue tip needs to be pressed lightly against the bottom of your top teeth. You need to create a small space to push air thorough, small enough that it makes a hissing sound as it escapes. That’s the “fricative” part. Fricatives are sounds where you force air through a small space and the air molecules start jostling each other and make a high-frequency hissing noise. Now, it won’t be as loud when you’re forcing air between your upper teeth and tongue as it is, for example, when you’re making an “s”, but it should still be noticeable.
So, to review, put the tip of your tongue against the bottom of your top teeth. Blow air through the thin space between your tongue and your teeth so that it creates a (not very loud) hissing sound. Now try voicing the sound (vibrating your vocal folds) as you do so. That’s it! You’ve got both of the English “th” sounds down.
If you’d like some more help, I really like this video, and it has some super-cool slow-motion videos. The lady who made it has a website focusing on English pronunciation which has some great resources. Good luck!
A lot of us, as literate English speakers, have probably experienced that queasy moment of dread when you’re writing something on the computer and suddenly get a squiggly red line under a word you use all the time. You look at the suggested spellings… and none of them are the word you wanted. If you’re like me, at this point you hop online really quickly to make sure the word means what you thought it did and that you’re not butchering the spelling too horribly. Or maybe you turn to the dictionary you keep on your desk. Or maybe you turn to someone sitting next to you and ask “Is this a real word?”.
Oh, this? It’s just the pocket edition. The full one is three hundred volumes and comes with an elephant named George to carry it around your house. And it’s covered in gold. This edition is only bound in unicorn skin but it’s fine for a quick desk reference.The underlying assumption behind the search to see if someone else uses the word is that, if they don’t, you can’t either. It’s not a “real word”. Which begs the question: what makes a word real? Is there a moment of Pinocchio-like transformation where the hollow wooden word someone created suddenly takes on life and joins the ranks of the English language to much back-slapping and cigar-handing from the other vetted words? Is there a little graduation party where the word gets a diploma from the OED and suddenly it’s okay to use it whenever you want? Or does it get hired by the spelling board and get to work right away?
OK, so that was getting a bit silly, but my point is that most people have the vague notion that there’s a distinction between “real” words and “fake” words that’s pretty hard and fast. Like most slang words and brand names are fake words. I like to call this the Scrabble distinction. If you can play it in Scrabble, it counts and you can put it in a paper or e-mail and no one will call you on it. If you can’t, it’s a fake word and you use it at your own risk. Dictionaries play a large part in determining which is which, right? The official Scrabble dictionary is pretty conservative: it doesn’t have d’oh in it for example. But it’s also not without controversy. The first official Scrabble dictionary, for example, didn’t have “granola” in it, which the Oxford English Dictionary (the great grand-daddy of English dictionaries and probably the most complete record ever complied of the lexicon of any language ever) notes was first used in 1886 and I think most of us would agree is a “real” word.
The line is even blurrier than that, though. English is a language with a long and rich written tradition. In some ways, that’s great. We’ve got a lot more information on how words used to be pronounced than we would have otherwise and a lot of diachronic information. (That’s information about how the language has changed over time. 😛 ) But if you’ve been exposed mainly to the English tradition, as I have, you tend to forget that writing isn’t inseparable from spoken language. They’re two different things and there are a lot of traditions that aren’t writing-based. Consider, for example, the Odù Ifá, an entirely oral divination text from Nigeria that sometimes gets compared to the bible or the Qur’an. In the cultures I was raised in, the thought of a sacred text that you can’t read is strange, but that’s just part of the cultural lens that Isee the world through; I shouldn’t project that bias onto other cultures.
So non-literary cultures still need to add words to their lexicons, right? But how do they know which words are “real” without dictionaries? It depends. Sometimes it just sort of happens organically. We see this in English too. Think about words associated with texting or IMing like “lol” or “brb” (that’s “laughing out loud” and “be right back” for those of you who are still living under rocks). I’ve noticed people saying these in oral conversations more and more and I wouldn’t be surprised if in fifty years “burb” started showing up in dictionaries. But even cultures which have only had writing systems for a very short amounts of time have gatekeepers. Navajo, which has only been written since around 1940, is a great example. Peter Ladefoged shares the following story in Phonetic Data Analysis:
One of our former UCLA linguistics students who is a Navajo tells how she was once giving a talk in a Navajo community. She was showing how words could be put together to create new words (such as sweet + heart creates a word with an entirely new meaning). When she was explaining this an elder called out: ‘Stop this blasphemy! Only the gods can create words.’ The Navajo language is holy in a way that is very foreign to most of us (p. 13).
So in Navajo you have elders and religious leaders who are the guardians of the language and serve as the final authorities. (FUN FACT: “authority” comes from the same root as “author”. See how writing-dependent English is?) There are always gray areas though. Language is, after all, incredibly complex. I’ll leave you one case to think about.
“Rammaflagit.” That’s ɹæm.ə.flæʒ.ɪt in the international phonetic alphabet. (I remember how thrilled my dad was when I told him I was studying IPA in college.) I hear it all the time and it means something like “gosh darn it”, sort of a bolderized curse word. Real word or not? The dictionaries say “no”, but the people who I’ve heard using it would clearly say “yes”. What do you think?