This is something I’ve written about before, but I’ve recently had several discussions with people who say they don’t find it odd to refer to a women as a female. Personally, I don’t like being called “a female” becuase its a term I to associate strongly with talking about animals. (Plus, it makes you sound like a Ferengi.) I would also protest men being called males, for the same reason, but my intuition is that that doesn’t happen as often. I’m willing to admit that my intuition may be wrong in this case, though, so I’ve decided to take a more data-driven approach. I had two main questions:
- Do “male” and “female” get used as nouns at different rates?
- Does one of these terms get used more often?
Data collection
I used the Twitter public API to collect two thousand English tweets, one thousand each containing the exact string “a male” and “a female”. I looked for these strings to help get as many tweets as possible with “male” or “female” used as a noun. “A” is what linguist call a determiner, and a determiner has to have a noun after it. It doesn’t have to be the very next word, though; you can get an adjective first, like so:
- A female mathematician proved the theorm.
- A female proved the theorm.
So this will let me directly compare these words in a situation where we should only be able to see a limited number of possible parts of speech & see if they differ from each other. Rather than tagging two thousand tweets by hand, I used a Twitter specific part-of-speech tagger to tag each set of tweets.
A part of speech tagger is a tool that guesses the part of speech of every word in a text. So if you tag a sentence like “Apples are tasty”, you should get back that “apples” is a plural noun, “are” is a verb and “tasty” is an adjective. You can try one out for yourself on-line here.
Parts of Speech
In line with my predictions, every instance of “male” or “female” was tagged as either a noun, an adjective or a hashtag. (I went through and looked at the hashtags and they were all porn bots. #gross #hazardsOfTwitterData)
However, not every noun was tagged as the same type of noun. I saw three types of tags in my data: NN (regular old noun), NNS (plural noun) and, unexpectedly, NNP (proper noun, singular). (If you’re confused by the weird upper case abbreviations, they’re the tags used in the Penn Treebank, and you can see the full list here.) In case it’s been a while since you studied parts of speech, proper nouns are things like personal or place names. The stuff that tend to get capitalized in English. The examples from the Penn Treebank documentation include “Motown”, “Venneboerger”, and “Czestochwa”. I wouldn’t consider either “female” or “male” a name, so it’s super weird that they’re getting tagged as proper nouns. What’s even weirder? It’s pretty much only “male” that’s getting tagged as a proper noun, as you can see below:
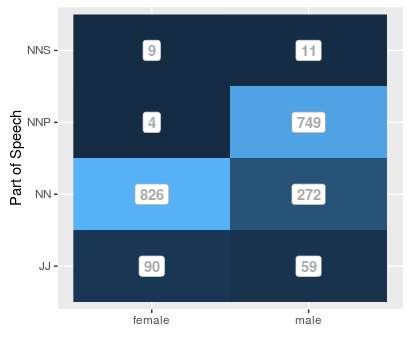
The differences in tagged POS between “male” and “female” was super robust(X2(6, N = 2033) = 1019.2, p <.01.). So what’s happening here? My first thought was that it might be that, for some reason, “male” is getting capitalized more often and that was confusing the tagger. But when I looked into, there wasn’t a strong difference between the capitalization of “male” and “female”: both were capitalized about 3% of the time.
My second thought was that it was a weirdness showing up becuase I used a tagger designed for Twitter data. Twitter is notoriously “messy” (in the sense that it can be hard for computers to deal with) so it wouldn’t be surprising if tagging “male” as a proper noun is the result of the tagger being trained on Twitter data. So, to check that, I re-tagged the same data using the Stanford POS tagger. And, sure enough, the weird thing where “male” is overwhelming tagged as a proper noun disappeared.

So it looks like “male” being tagged as a proper noun is an artifact of the tagger being trained on Twitter data, and once we use a tagger trained on a different set of texts (in this case the Wall Street Journal) there wasn’t a strong difference in what POS “male” and “female” were tagged as.
Rate of Use
That said, there was a strong difference between “a female” and “a male”: how often they get used. In order to get one thousand tweets with the exact string “a female”, Twitter had to go back an hour and thirty-four minutes. In order to get a thousand tweets with “a male”, however, Twitter had to go back two hours and fifty eight minutes. Based on this sample, “a female” gets said almost twice as often as “a male”.
So what’s the deal?
- Do “male” and “female” get used as nouns at different rates? It depends on what tagger you use! In all seriousness, though, I’m not prepared to claim this based on the dataset I’ve collected.
- Does one of these terms get used more often? Yes! Based on my sample, Twitter users use “a female” about twice as often as “a male”.
I think the greater rate of use of “a female” that points to the possibility of an interesting underlying difference in how “male” and “female” are used, one that calls for a closer qualitative analysis. Does one term get used to describe animals more often than the other? What sort of topics are people talking about when they say “a male” and “a female”? These questions, however, will have to wait for the next blog post!
In the meantime, I’m interested in getting more opinions on this. How do you feel about using “a male” and “a female” as nouns to talk about humans? Do they sound OK or strike you as odd?
My code and is available on my GitHub.
.jpg)