We’re all familiar with the sensation of sound so loud we can actually feel it: the roar of a jet engine, the palpable vibrations of a loud concert, a thunderclap so close it shakes the windows. It may surprise you to learn, however, that that’s not the only way in which we “feel” sounds. In fact, recent research suggests that tactile information might be just as important as sound in some cases!
What was that? I couldn’t hear you, you were touching too gently.I’ve already talked about how we cansee sounds, and the role that sound plays in speech perception before. But just how much overlap is there between our sense of touch and hearing? There is actually pretty strong evidence that what we feel can actually override what we’re hearing. Yau et. al. (2009), for example, found that tactile expressions of frequency could override auditory cues. In other words, you might hear two identical tones as different if you’re holding something that is vibrating faster or slower. If our vision system had a similar interplay, we might think that a person was heavier if we looked at them while holding a bowling ball, and lighter if we looked at them while holding a volleyball.
And your sense of touch can override your ears (not that they were that reliable to begin with…) when it comes to speech as well. Gick and Derrick (2013) have found that tactile information can override auditory input for speech sounds. You can be tricked into thinking that you heard a “peach” rather than “beach”, for example, if you’re played the word “beach” and a puff of air is blown over your skin just as you hear the “b” sound. This is because when an English speaker says “peach”, they aspirate the “p”, or say it with a little puff of air. That isn’t there when they say the “b” in “beach”, so you hear the wrong word.
Which is all very cool, but why might this be useful to us as language-users? Well, it suggests that we use a variety of cues when we’re listening to speech. Cues act as little road-signs that point us towards the right interpretation. By having access to a lots of different cues, we ensure that our perception is more robust. Even when we lose some cues–say, a bear is roaring in the distance and masking some of the auditory information–you can use the others to figure out that your friend is telling you that there’s a bear. In other words, even if some of the road-signs are removed, you can still get where you’re going. Language is about communication, after all, and it really shouldn’t be surprising that we use every means at our disposal to make sure that communication happens.
A question that has been posed to me with some frequency recently is why some things are untranslatable. A good example of this is posts such as this, which has the supposedly untranslatable word alongside—ironically—its translation. But I think that if we ask why certain words can’t be translated, we’re actually asking the wrong question. The right question is: why do we think anything at all can be translated?
Why is it that we shy away from trying to translate dépaysement but feel quite strongly that apomme is the same thing as an apple? While a French speaker and and English speaker would probably use the those respective words to ask for the same piece of fruit from a fruit bowl, the phrase “the apple of my eye” is better tranlsted into French as “prunelle de mes yeux”. And if you asked for the prunelle from a fruit bowl, you’d be given something an English speaker would call a plum. So while we think of these two words as the same, on some level, it cannot be denied that they play different roles in their respective languages. No one claims either “apple” or “pomme” are untranslatable, though.
Well, let’s talk a little about what translation is. In linguistics, the standard when discussing languages that the reader is not familiar with (and, since descriptive linguists often work with languages that have a few dozen speakers, this is not uncommon) is to use three lines. The first is in the original language (usually in the International Phonetic Alphabet), the second line is a morpheme-by-morpheme translation and the third is a ‘sense translation’, which is how an English speaker might have expressed the same thought. (Morphemes, you may be aware, are the smallest unit of language to contain meaning. So the single word “dogs” has two morphemes. “Dog”, which has the meaning of canis familiaris, and “-s”, which tells us that there’s more than one.)
While we tend to idealize translation as the first, a word-to-word correspondence. But even that’s a bit of a simplification, for you’ll often hear people referring to the “literal” translation of something like an idiom, while the “actual” translation is something that maintains the sense but not the wording. The idea that it’s the sense that translations should capture and not the exact wording can sometimes be taken to extremes. Consider FItzgerald’s “translation” of the The Rubáiyát of Omar Khayyám, which in places diverges wildly from the source material. It is true translation, in a morpheme-by-morpheme sense? No. But we still accept it as essentially the same material in two different languages.
And if we accept that on the level of the poem, then I feel like we also have to accept it on the level of the word. It may take more or fewer words to express the same idea in different languages, but if we believe that we’re capable of sharing thoughts between people (Richard Wright once called language “a very inefficient means of telepathy”) then shuttling them between languages, no matter how difficult the transition, should also be possible. If anything is translatable, than everything has to be.
Of course, accounting for and explaining the cultural baggage associated with a certain term or replicating levels of meaning below the morpheme may pose a greater challenge. But that’s a post for another day.
Since I’m teaching Language and Society this quarter, this is a question that I anticipate coming up early and often. Accents–or dialects, though the terms do differ slightly–are one of those things in linguistics that is effortlessly fascinating. We all have experience with people who speak our language differently than we do. You can probably even come up with descriptors for some of these differences. Maybe you feel that New Yorkers speak nasally, or that Southerners have a drawl, or that there’s a certain Western twang. But how did these differences come about and how are perpetuated?
Clearly people have Accents because they’re looking for a nice little sub-compact commuter car.
First, two myths I’d like to dispel.
Only some people have an accent or speak a dialect. This is completely false with a side of flat-out wrong. Every single person who speaks or signs a language does so with an accent. We sometimes think of newscasters, for example, as “accent-less”. They do have certain systematic variation in their speech, however, that they share with other speakers who share their social grouping… and that’s an accent. The difference is that it’s one that tends to be seen as “proper” or “correct”, which leads nicely into myth number two:
Some accents are better than others. This one is a little more tricky. As someone who has a Southern-influenced accent, I’m well aware that linguistic prejudice exists. Some accents (such as the British “received pronunciation”) are certainly more prestigious than others (oh, say, the American South). However, this has absolutely no basis in the language variation itself. No dialect is more or less “logical” than any other, and geographical variation of factors such as speech rate has no correlation with intelligence. Bottom line: the differing perception of various accents is due to social, and not linguistic, factors.
Now that that’s done with, let’s turn to how we get accents in the first place. To begin with, we can think of an accent as a collection of linguistic features that a group of people share. By themselves, these features aren’t necessarily immediately noticeable, but when you treat them as a group of factors that co-varies it suddenly becomes clearer that you’re dealing with separate varieties. Which is great and all, but let’s pull out an example to make it a little clearer what I mean.
Imagine that you have two villages. They’re relatively close and share a lot of commerce and have a high degree of intermarriage. This means that they talk to each other a lot. As a new linguistic change begins to surface (which, as languages are constantly in flux, is inevitable) it spreads through both villages. Let’s say that they slowly lose the ‘r’ sound. If you asked a person from the first village whether a person from the second village had an accent, they’d probably say no at that point, since they have all of the same linguistic features.
But what if, just before they lost the ‘r’ sound, an unpassable chasm split the two villages? Now, the change that starts in the first village has no way to spread to the second village since they no longer speak to each other. And, since new linguistic forms pretty much come into being randomly (which is why it’s really hard to predict what a language will sound like in three hundred years) it’s very unlikely that the same variant will come into being in the second village. Repeat that with a whole bunch of new linguistic forms and if, after a bridge is finally built across the chasm, you ask a person from the first village whether a person from the second village has an accent, they’ll probably say yes. They might even come up with a list of things they say differently: we say this and they say that. If they were very perceptive, they might even give you a list with two columns: one column the way something’s said in their village and the other the way it’s said in the second village.
But now that they’ve been reunited, why won’t the accents just disappear as they talk to each other again? Well, it depends, but probably not. Since they were separated, the villages would have started to develop their own independent identities. Maybe the first village begins to breed exceptionally good pigs while squash farming is all the rage in the second village. And language becomes tied that that identity. “Oh, I wouldn’t say it that way,” people from the first village might say, “people will think I raise squash.” And since the differences in language are tied to social identity, they’ll probably persist.
Obviously this is a pretty simplified example, but the same processes are constantly at work around us, at both a large and small scale. If you keep an eye out for them, you might even notice them in action.
So, quick review: understanding speechis hard to model and the first model we discussed, motor theory, while it does address some problems, leaves something to be desired. The big one is that it doesn’t suggest that the main fodder for perception is the acoustic speech signal. And that strikes me as odd. I mean, we’re really used to thinking about hearing speech as a audio-only thing. Telephones and radios work perfectly well, after all, and the information you’re getting there is completely audio. That’s not to say that we don’t use visual, or, heck, even tactile data in speech perception. The McGurk effect, where a voice saying “ba” dubbed over someone saying “ga” will be perceived as “da” or “tha”, is strong evidence that we can and do use our eyes during speech perception. And there’s even evidence that a puff of air on the skin will change our perception of speech sounds. But we seem to be able to get along perfectly well without these extra sensory inputs, relying on acoustic data alone.
This theory sounds good to me. Sorry, I’ll stop.Ok, so… how do we extract information from acoustic data? Well, like I’ve said a couple time before, it’s actually a pretty complex problem. There’s no such thing as “invariance” in the speech signal and that makes speech recognition monumentally hard. We tend not to think about it because humans are really, really good at figuring out what people are saying, but it’s really very, very complex.
You can think about it like this: imagine that you’re looking for information online about platypuses. Except, for some reason, there is no standard spelling of platypus. People spell it “platipus”, “pladdypuss”, “plaidypus”, “plaeddypus” or any of thirty or forty other variations. Even worse, one person will use many different spellings and may never spell it precisely the same way twice. Now, a search engine that worked like our speech recognition works would not only find every instance of the word platypus–regardless of how it was spelled–but would also recognize that every spelling referred to the same animal. Pretty impressive, huh? Now imagine that every word have a very variable spelling, oh, and there are no spaces between words–everythingisjustruntogetherlikethisinonelongspeechstream. Still not difficult enough for you? Well, there is also the fact that there are ambiguities. The search algorithm would need to treat “pladypuss” (in the sense of a plaid-patterned cat) and “palattypus” (in the sense of the venomous monotreme) as separate things. Ok, ok, you’re right, it still seems pretty solvable. So let’s add the stipulation that the program needs to be self-training and have an accuracy rate that’s incredibly close to 100%. If you can build a program to these specifications, congratulations: you’ve just revolutionized speech recognition technology. But we already have a working example of a system that looks a heck of a lot like this: the human brain.
So how does the brain deal with the “different spellings” when we say words? Well, it turns out that there are certain parts of a word that are pretty static, even if a lot of other things move around. It’s like a superhero reboot: Spiderman is still going to be Peter Parker and get bitten by a spider at some point and then get all moody and whine for a while. A lot of other things might change, but if you’re only looking for those criteria to figure out whether or not you’re reading a Spiderman comic you have a pretty good chance of getting it right. Those parts that are relatively stable and easy to look for we call “cues”. Since they’re cues in the acoustic signal, we can be even more specific and call them “acoustic cues”.
If you think of words (or maybe sounds, it’s a point of some contention) as being made up of certain cues, then it’s basically like a list of things a house-buyer is looking for in a house. If a house has all, or at least most, of the things they’re looking for, than it’s probably the right house and they’ll select that one. In the same way, having a lot of cues pointing towards a specific word makes it really likely that that word is going to be selected. When I say “selected”, I mean that the brain will connect the acoustic signal it just heard to the knowledge you have about a specific thing or concept in your head. We can think of a “word” as both this knowledge and the acoustic representation. So in the “platypuss” example above, all the spellings started with “p” and had an “l” no more than one letter away. That looks like a pretty robust cue. And all of the words had a second “p” in them and ended with one or two tokens of “s”. So that also looks like a pretty robust queue. Add to that the fact that all the spellings had at least one of either a “d” or “t” in between the first and second “p” and you have a pretty strong template that would help you to correctly identify all those spellings as being the same word.
Which all seems to be well and good and fits pretty well with our intuitions (or mine at any rate). But that leaves us with a bit of a problem: those pesky parts of Motor Theory that are really strongly experimentally supported. And this model works just as well for motor theory too, just replace the “letters” with specific gestures rather than acoustic cues. There seems to be more to the story than either the acoustic model or the motor theory model can offer us, though both have led to useful insights.
Ok, so like I talked about in my previoustwo posts, modelling speech perception is an ongoing problem with a lot of hurdles left to jump. But there are potential candidate theories out there, all of which offer good insight into the problem. The first one I’m going to talk about is motor theory.
So your tongue is like the motor body and the other person’s ear are like the load cell…So motor theory has one basic premise and three major claims. The basic premise is a keen observation: we don’t just perceive speech sounds, we also make them. Whoa, stop the presses. Ok, so maybe it seems really obvious, but motor theory was really the first major attempt to model speech perception that took this into account. Up until it was first posited in the 1960’s , people had pretty much been ignoring that and treating speech perception like the only information listeners had access to was what was in the acoustic speech signal. We’ll discuss that in greater detail, later, but it’s still pretty much the way a lot of people approach the problem. I don’t know of a piece of voice recognition software, for example, that include an anatomical model.
So what’s the fact that listeners are listener/speakers get you? Well, remember how there aren’t really invariant units in the speech signal? Well, if you decide that what people are actually perceiving aren’t actually a collection of acoustic markers that point to one particular language sound but instead the gestures needed to make up that sound, then suddenly that’s much less of a problem. To put it in another way, we’re used to thinking of speech being made up of a bunch of sounds, and that when we’re listening speech we’re deciding what the right sounds are and from there picking the right words. But from a motor theory standpoint, what you’re actually doing when you’re listening to speech is deciding what the speaker’s doing with their mouth and using that information to figure out what words they’re saying. So in the dictionary in your head, you don’t store words as strings of sounds but rather as strings of gestures.
If you’re like me when I first encountered this theory, it’s about this time that you’re starting to get pretty skeptical. I mean, I basically just said that what you’re hearing is the actual movement of someone else’s tongue and figuring out what they’re saying by reverse engineering it based on what you know your tongue is doing when you say the same word. (Just FYI, when I say tongue here, I’m referring to the entire vocal tract in its multifaceted glory, but that’s a bit of a mouthful. Pun intended. 😉 ) I mean, yeah, if we accept this it gives us a big advantage when we’re talking about language acquisition–since if you’re listening to gestures, you can learn them just by listening–but still. It’s weird. I’m going to need some convincing.
Well, let’s get back to the those three principles I mentioned earlier, which are taken from Galantucci, Flower and Turvey’s excellent review of motor theory.
Speech is a weird thing to perceive and pretty much does its own thing. I’ve talked about this at length, so let’s just take that as a given for now.
When we’re listening to speech, we’re actually listening to gestures. We talked about that above.
We use our motor system to help us perceive speech.
Ok, so point three should jump out at you a bit. Why? Of these three points, its the easiest one to test empirically. And since I’m a huge fan of empirically testing things (Science! Data! Statistics!) we can look into the literature and see if there’s anything that supports this. Like, for example, a study that shows that when listening to speech, our motor cortex gets all involved. Well, it turns out that there are lots of studies that show this. You know that term “active listening”? There’s pretty strong evidence that it’s more than just a metaphor; listening to speech involves our motor system in ways that not all acoustic inputs do.
So point three is pretty well supported. What does that mean for point two? It really depends on who you’re talking to. (Science is all about arguing about things, after all.) Personally, I think motor theory is really interesting and address a lot of the problems we face in trying to model speech perception. But I’m not ready to swallow it hook, line and sinker. I think Robert Remez put it best in the proceedings of Modularity and The Motor Theory of Speech Perception:
I think it is clear that Motor Theory is false. For the other, I think the evidence indicates no less that Motor Theory is essentially, fundamentally, primarily and basically true. (p. 179)
On the one hand, it’s clear that our motor system is involved in speech perception. On the other, I really do think that we use parts of the acoustic signal in and of themselves. But we’ll get into that in more depth next week.
Ok, so, a couple weeks ago I talked about why speech perception was hard to model. Really, though, what I talked about was why building linguistic models is a hard task. There’s a couple other thorny problems that plague people who work with speech perception, and they have to do with the weirdness of the speech signal itself. It’s important to talk about because it’s on account of dealing with these weirdnesses that some theories of speech perception themselves can start to look pretty strange. (Motor theory, in particular, tends to sound pretty messed-up the first time you encounter it.)
The speech signal and the way we deal with it is really strange in two main ways.
The speech signal doesn’t contain invariant units.
We both perceive and produce speech in ways that are surprisingly non-linear.
So what are “invariant units” and why should we expect to have them? Well, pretty much everyone agrees that we store words as larger chunks made up of smaller chunks. Like, you know that the word “beet” is going to be made with the lips together at the beginning for the “b” and your tongue behind your teeth at the end for the “t”. And you also know that it will have certain acoustic properties; a short break in the signal followed by a small burst of white noise in a certain frequency range (that’s a the “b” again) and then a long steady state for the vowel and then another sudden break in the signal for the “t”. So people make those gestures and you listen for those sounds and everything’s pretty straightforwards right? Weeellllll… not really.
It turns out that you can’t really be grabbing onto certain types of acoustic queues because they’re not always reliably there. There are a bunch of different ways to produce “t”, for example, that run the gamut from the way you’d say it by itself to something that sound more like a “w” crossed with an “r”. When you’re speaking quickly in an informal setting, there’s no telling where on that continuum you’re going to fall. Even with this huge array of possible ways to produce a sound, however, you still somehow hear is at as “t”.
And even those queues that are almost always reliably there vary drastically from person to person. Just think about it: about half the population has a fundamental frequency, or pitch, that’s pretty radically different from the other half. The old interplay of biological sex and voice quality thing. But you can easily, effortlessly even, correct for the speaker’s gender and understand the speech produced by men and women equally well. And if a man and woman both say “beet”, you have no trouble telling that they’re saying the same word, even though the signal is quite different in both situations. And that’s not a trivial task. Voice recognition technology, for example, which is overwhelmingly trained on male voices, often has a hard time understanding women’s voices. (Not to mention different accents. What that says about regional and sex-based discrimination is a topic for another time.)
And yet. And yet humans are very, very good a recognizing speech. How? Well linguists have made some striking progress in answering that question, though we haven’t yet arrived at an answer that makes everyone happy. And the variance in the signal isn’t the only hurdle facing humans as the recognize the vocal signal: there’s also the fact that the fact that we are humans has effects on what we can hear.
Ooo, pretty rainbow. Thorny problem, though: this shows how we hear various frequencies better or worse. The sweet spot is right around 300 kHz or so. Which, coincidentally, just so happens to be where we produce most of the noise in the speech signal. But we do still produce information at other frequencies and we do use that in speech perception: particularly for sounds like “s” and “f”.
We can think of the information available in the world as a sheet of cookie dough. This includes things like UV light and sounds below 0 dB in intensity. Now imagine a cookie-cutter. Heck, make it a gingerbread man. The cookie-cutter represents the ways in which the human body limits our access to this information. There are just certain things that even a normal, healthy human isn’t capable of perceiving. We can only hear the information that falls inside the cookie cutter. And the older we get, the smaller the cookie-cutter becomes, as we slowly lose sensitivity in our auditory and visual systems. This makes it even more difficult to perceive speech. Even though it seems likely that we’ve evolved our vocal system to take advantage of the way our perceptual system works, it still makes the task of modelling speech perception even more complex.
So the good folks over at Userdesign asked me to review their newest volume, Punctuation..? and I was happy to oblige. Linguists rarely study punctuation (it falls under the sub-field orthography, or the study of writing systems) but what we do study is the way that language attitudes and punctuation come together. I’ve written before about language attitudes when it come to grammar instruction and the strong prescriptive attitudes of most grammar instruction books. What makes this book so interesting is that it is partly prescriptive and partly descriptive. Since a descriptive bent in a grammar instruction manual is rare, I thought I’d delve into that a bit.
Image copyright Userdesign, used with permission. (Click for link to site.)
So, first of all, how about a quick review of the difference between a descriptive and prescriptive approach to language?
Descriptive: This is what linguists do. We don’t make value or moral judgments about languages or language use, we just say what’s going on as best we can. You can think of it like an anthropological ethnography: we just describe what’s going on.
Prescriptive: This is what people who write letters to the Times do. They have a very clear idea of what’s “right” and “wrong” with regards to language use and are all to happy to tell you about it. You can think of this like a manner book: it tells you what the author thinks you should be doing.
As a linguist, my relationship with language is mainly scientific, so I have a clear preference for a descriptive stance. An ichthyologist doesn’t tell octopi, “No, no, no, you’re doing it all wrong!” after all. At the same time, I live in a culture which has very rigid expectations for how an educated individual should write and sound, and if I want to be seen as an educated individual (and be considered for the types of jobs only open to educated individuals) you better believe I’m going to adhere to those societal standards. The problem comes when people have a purely prescriptive idea of what grammar is and what it should be. That can lead to nasty things like linguistic discrimination. I.e., language B (and thus all those individuals who speak language B) is clearly inferior to language A because they don’t do things properly. Since I think we can all agree that unfounded discrimination of this type is bad, you can see why linguists try their hardest to avoid value judgments of languages.
As I mentioned before, this book is a fascinating mix of prescriptive and descriptive snippets. For example, the author says this about exclamation points: “In everyday writing, the exclamation mark is often overused in the belief that it adds drama and excitement. It is, perhaps the punctuation mark that should be used with the most restraint” (p 19). Did you notice that “should'”? Classic marker of a prescriptivist claiming their territory. But then you have this about Guillements: “Guillements are used in several languages to indicate passages of speech in the same way that single and double quotation marks (” “”) are used in the English language” (p. 22). (Guillements look like this, since I know you were wondering; « and ». ) See, that’s a classical description of what a language does, along with parallels drawn to another, related, languages. It may not seem like much, but try to find a comparably descriptive stance in pretty much any widely-distributed grammar manual. And if you do, let me know so that I can go buy a copy of it. It’s change, and it’s positive change, and I’m a fan of it. Is this an indication of a sea-change in grammar manuals? I don’t know, but I certainly hope so.
Over all, I found this book fascinating (though not, perhaps, for the reasons the author intended!). Particularly because it seems to stand in contrast to the division that I just spent this whole post building up. It’s always interesting to see the ways that stances towards language can bleed and melt together, for all that linguists (and I include myself here) try to show that there’s a nice, neat dividing line between the evil, scheming prescriptivists and the descriptivists in their shining armor here to bring a veneer of scientific detachment to our relationship with language. Those attitudes can and do co-exist. Data is messy. Language is complex. Simple stories (no matter how pretty we might think them) are suspicious. But these distinctions can be useful, and I’m willing to stand by the descriptivist/prescriptivist, even if it’s harder than you might think to put people in one camp or the others.
But beyond being an interesting study in language attitdues, it was a fun read. I learned lots of neat little factoids, which is always a source of pure joy for me. (Did you know that this symbol: ¶ is called a Pilcrow? I know right? I had no idea either; I always just called it the paragraph mark.)
So this is a kick-off post for a series of posts about various speech perception models. Speech perception models, you ask? Like, attractive people who are good at listening?
Not only can she discriminate velar, uvular and pharyngeal fricatives with 100% accuracy, but she can also do it in heels.No, not really. (I wish that was a job…) I’m talking about a scientific model of how humans perceive speech sounds. If you’ve ever taken an introductory science class, you already have some experience with scientific models. All of Newton’s equations are just a way of generalizing general principals generally across many observed cases. A good model has both explanatory and predictive power. So if I say, for example, that force equals mass times acceleration, then that should fit with any data I’ve already observed as well as accurately describe new observations. Yeah, yeah, you’re saying to yourself, I learned all this in elementary school. Why are you still going on about it? Because I really want you to appreciate how complex this problem is.
Let’s take an example from an easier field, say, classical mechanics. (No offense physicists, but y’all know it’s true.) Imagine we want to model something relatively simple. Perhaps we want to know whether a squirrel who’s jumping from one tree to another is going to make. What do we need to know? And none of that “assume the squirrel is a sphere and there’s no air resistance” stuff, let’s get down to the nitty-gritty. We need to know the force and direction of the jump, the locations of the trees, how close the squirrel needs to get to be able to hold on, what the wind’s doing, air resistance and how that will interplay with the shape of the squirrel, the effects of gravity… am I missing anything? I feel like I might be, but that’s most of it.
So, do you notice something that all of these things we need to know the values of have in common? Yeah, that’s right, they’re easy to measure directly. Need to know what the wind’s doing? Grab your anemometer. Gravity? To the accelerometer closet! How far apart the trees are? It’s yardstick time. We need a value , we measure a value, we develop a model with good predictive and explanatory power (You’ll need to wait for your simulations to run on your department’s cluster. But here’s one I made earlier so you can see what it looks like. Mmmm, delicious!) and you clean up playing the numbers on the professional squirrel-jumping circuit.
Let’s take a similarly simple problem from the field of linguistics. You take a person, sit them down in a nice anechoic chamber*, plop some high quality earphones on them and play a word that could be “bite” and could be “bike” and ask them to tell you what they heard. What do you need to know to decide which way they’ll go? Well, assuming that your stimuli is actually 100% ambiguous (which is a little unlikely) there a ton of factors you’ll need to take into account. Like, how recently and often has the subject heard each of the words before? (Priming and frequency effects.) Are there any social factors which might affect their choice? (Maybe one of the participant’s friends has a severe overbite, so they just avoid the word “bite” all together.) Are they hungry? (If so, they’ll probably go for “bite” over “bike”.) And all of that assumes that they’re a native English speaker with no hearing loss or speech pathologies and that the person’s voice is the same as theirs in terms of dialect, because all of that’ll bias the listener as well.
The best part? All of this is incredibly hard to measure. In a lot of ways, human language processing is a black box. We can’t mess with the system too much and taking it apart to see how it works, in addition to being deeply unethical, breaks the system. The best we can do is tap a hammer lightly against the side and use the sounds of the echos to guess what’s inside. And, no, brain imaging is not a magic bullet for this. It’s certainly a valuable tool that has led to a lot of insights, but in addition to being incredibly expensive (MRI is easily more than a grand per participant and no one has ever accused linguistics of being a field that rolls around in money like a dog in fresh-cut grass) we really need to resist the urge to rely too heavily on brain imaging studies, as a certain dead salmon taught us.
But! Even though it is deeply difficult to model, there has been a lot of really good work done on towards a theory of speech perception. I’m going to introduce you to some of the main players, including:
Motor theory
Acoustic/auditory theory
Double-weak theory
Episodic theories (including Exemplar theory!)
Don’t worry if those all look like menu options in an Ethiopian restaurant (and you with your Amharic phrasebook at home, drat it all); we’ll work through them together. Get ready for some mind-bending, cutting-edge stuff in the coming weeks. It’s going to be [fʌn] and [fʌnetɪk]. 😀
*Anechoic chambers are the real chambers of secrets.
So I found a wonderful free app that lets you learn Yoruba, or at least Yoruba words, and posted about it on Google plus. Someone asked a very good question: why am I interested in Yoruba? Well, I’m not interested just in Yoruba. In fact, I would love to learn pretty much any western African language or, to be a little more precise, any Niger-Congo language.
This map’s color choices make it look like a chocolate-covered ice cream cone.Why? Well, not to put too fine a point on it, I’ve got a huge language crush on them. Whoa there, you might be thinking, you’re a linguist. You’re not supposed to make value judgments on languages. Isn’t there like a linguist code of ethics or something? Well, not really, but you are right. Linguists don’t usually make value judgments on languages. That doesn’t mean we can’t play favorites! And West African languages are my favorites. Why? Because they’re really phonologically and phonetically interesting. I find the sounds and sound systems of these languages rich and full of fascinating effects and processes. Since that’s what I study within linguistics, it makes sense that that’s a quality I really admire in a language.
What are a few examples of Niger-Congo sound systems that are just mind blowing? I’m glad you asked.
Yoruba: Yoruba has twelve vowels. Seven of them are pretty common (we have all but one in American English) but if you say four of them nasally, they’re different vowels. And if you say a nasal vowel when you’re not supposed to, it’ll change the entire meaning of a word. Plus? They don’t have a ‘p’ or an ‘n’ sound. That is crazy sauce! Those are some of the most widely-used sounds in human language. And Yoruba has a complex tone system as well. You probably have some idea of the level of complexity that can add to a sound system if you’ve ever studied Mandarin, or another East Asian language. Seriously, their sound system makes English look childishly simplistic.
Akan: There are several different dialects of Akan, so I’ll just stick to talking about Asante, which is the one used in universities and for official business. It’s got a crazy consonant system. Remember how Yoruba didn’t have an “n” sound? Yeah, in Akan they have nine. To an English speaker they all pretty much sound the same, but if you grew up speaking Akan you’d be able to tell the difference easily. Plus, most sounds other than “p”, “b”, “f” or “m” can be made while rounding the lips (linguists call this “labialized” and are completely different sounds). They’ve also got a vowel harmony system, which means you can’t have vowels later in a word that are completely different from vowels earlier in the word. Oh, yeah, and tones and a vowel nasalization distinction and some really cool tone terracing. I know, right? It’s like being a kid in a candy store.
But how did these language get so cool? Well, there’s some evidence that these languages have really robust and complex sound systems because the people speaking them never underwent large-scale migration to another Continent. (Obviously, I can’t ignore the effects of colonialism or the slave trade, but it’s still pretty robust.) Which is not to say that, say, Native American languages don’t have awesome sound systems; just just tend to be slightly smaller on average.
Now that you know how kick-ass these languages, I’m sure you’re chomping at the bit to hear some of them. Your wish is my command; here’s a song in Twi (a dialect of Akan) from one of my all-time-favorite musicians: Sarkodie. (He’s making fun of Ghanaian emigrants who forget their roots. Does it get any better than biting social commentary set to a sick beat?)
So the goal of linguistics is to find and describe the systematic ways in which humans use language. And boy howdy do we humans love using language systematically. A great example of this is internet memes.
What are internet memes? Well, let’s start with the idea of a “meme”. “Memes” were posited by Richard Dawkin in his book The Selfish Gene. He used the term to describe cultural ideas that are transmitted from individual to individual much like a virus or bacteria. The science mystique I’ve written about is a great example of a meme of this type. If you have fifteen minutes, I suggest Dan Dennett’s TED talk on the subject of memes as a much more thorough introduction.
So what about the internet part? Well, internet memes tend to be a bit narrower in their scope. Viral videos, for example, seem to be a separate category from intent memes even though they clearly fit into Dawkin’s idea of what a meme is. Generally, “internet meme” refers to a specific image and text that is associated with that image. These are generally called image macros. (For a through analysis of emerging and successful internet memes, as well as an excellent object lesson in why you shouldn’t scroll down to read the comments, I suggest Know Your Meme.) It’s the text that I’m particularly interested in here.
Memes which involve language require that it be used in a very specific way, and failure to obey these rules results in social consequences. In order to keep this post a manageable size, I’m just going to look at the use of language in the two most popular image memes, as ranked by memegenerator.net, though there is a lot more to study here. (I think a study of the differing uses of the initialisms MRW [my reaction when] and MFW [my face when] on imgur and 4chan would show some very interesting patterns in the construction of identity in the two communities. Particularly since the 4chan community is made up of anonymous individuals and the imgur community is made up of named individuals who are attempting to gain status through points. But that’s a discussion for another day…)
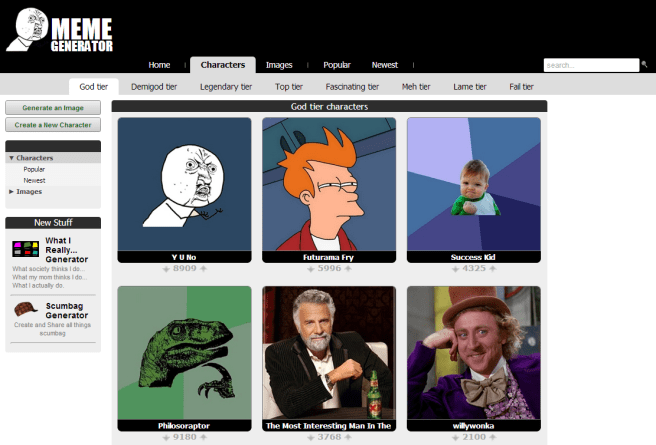
The God tier (i.e. most popular) characters at on the website Meme Generator as of February 23rd, 2013. Click for link to site. If you don’t recognize all of these characters, congratulations on not spending all your free time on the internet.
Without further ado, let’s get to the grammar. (I know y’all are excited.)
Y U No
This meme is particularly interesting because its page on Meme Generator already has a grammatical description.
The Y U No meme actually began as Y U No Guy but eventually evolved into simply Y U No, the phrase being generally followed by some often ridiculous suggestion. Originally, the face of Y U No guy was taken from Japanese cartoon Gantz’ Chapter 55: Naked King, edited, and placed on a pink wallpaper. The text for the item reads “I TXT U … Y U NO TXTBAK?!” It appeared as a Tumblr file, garnering over 10,000 likes and reblogs.
It went totally viral, and has morphed into hundreds of different forms with a similar theme. When it was uploaded to MemeGenerator in a format that was editable, it really took off. The formula used was : “(X, subject noun), [WH]Y [YO]U NO (Y, verb)?”. [Bold mine.]
A pretty good try, but it can definitely be improved upon. There are always two distinct groupings of text in this meme, always in impact font, white with a black border and in all caps. This is pretty consistent across all image macros. In order to indicate the break between the two text chunks, I will use — throughout this post. The chunk of text that appears above the image is a noun phrase that directly addresses someone or something, often a famous individual or corporation. The bottom text starts with “Y U NO” and finishes with a verb phrase. The verb phrase is an activity or action that the addressee from the first block of text could or should have done, and that the meme creator considers positive. It is also inflected as if “Y U NO” were structurally equivalent to “Why didn’t you”. So, since you would ask Steve Jobs “Why didn’t you donate more money to charity?”, a grammatical meme to that effect would be “STEVE JOBS — Y U NO DONATE MORE MONEY TO CHARITY”. In effect, this meme questions someone or thing who had the agency to do something positive why they chose not to do that thing. While this certainly has the potential to be a vehicle for social commentary, like most memes it’s mostly used for comedic effect. Finally, there is some variation in the punctuation of this meme. While no punctuation is the most common, an exclamation points, a question mark or both are all used. I would hypothesize that the the use of punctuation varies between internet communities… but I don’t really have the time or space to get into that here.
A meme (created by me using Meme Generator) following the guidelines outlined above.
Futurama Fry
This meme also has a brief grammatical analysis
The text surrounding the meme picture, as with other memes, follows a set formula. This phrasal template goes as follows: “Not sure if (insert thing)”, with the bottom line then reading “or just (other thing)”. It was first utilized in another meme entitled “I see what you did there”, where Fry is shown in two panels, with the first one with him in a wide-eyed expression of surprise, and the second one with the familiar half-lidded expression.
As an example of the phrasal template, Futurama Fry can be seen saying: “Not sure if just smart …. Or British”. Another example would be “Not sure if highbeams … or just bright headlights”. The main form of the meme seems to be with the text “Not sure if trolling or just stupid”.
This meme is particularly interesting because there seems to an extremely rigid syntactic structure. The phrase follow the form “NOT SURE IF _____ — OR _____”. The first blank can either be filled by a complete sentence or a subject complement while the second blank must be filled by a subject complement. Subject complements, also called predicates (But only by linguists; if you learned about predicates in school it’s probably something different. A subject complement is more like a predicate adjective or predicate noun.), are everything that can come after a form of the verb “to be” in a sentence. So, in a sentence like “It is raining”, “raining” is the subject complement. So, for the Futurama Fry meme, if you wanted to indicate that you were uncertain whther it was raining or sleeting, both of these forms would be correct:
NOT SURE IF IT’S RAINING — OR SLEETING
NOT SURE IF RAINING — OR SLEETING
Note that, if a complete sentence is used and abbreviation is possible, it must be abbreviated. Thus the following sentence is not a good Futurama Fry sentence:
*NOT SURE IF IT IS RAINING — OR SLEETING
This is particularly interesting because the “phrasal template” description does not include this distinction, but it is quite robust. This is a great example of how humans notice and perpetuate linguistic patterns that they aren’t necessarily aware of.
A meme (created by me using Meme Generator) following the guidelines outlined above. If you’re not sure whether it’s phonetics or phonology, may I recommend this post as a quick refresher?
So this is obviously very interesting to a linguist, since we’re really interested in extracting and distilling those patterns. But why is this useful/interesting to those of you who aren’t linguists? A couple of reasons.
I hope you find it at least a little interesting and that it helps to enrich your knowledge of your experience as a human. Our capacity for patterning is so robust that it affects almost every aspect of our existence and yet it’s easy to forget that, to let our awareness of that slip our of our conscious minds. Some patterns deserve to be examined and criticized, though, and linguistics provides an excellent low-risk training ground for that kind of analysis.
If you are involved in internet communities I hope you can use this new knowledge to avoid the social consequences of violating meme grammars. These consequences can range from a gentle reprimand to mockery and scorn The gatekeepers of internet culture are many, vigilant and vicious.
As with much linguistic inquiry, accurately noting and describing these patterns is the first step towards being able to use them in a useful way. I can think of many uses, for example, of a program that did large-scale sentiment analyses of image macros but was able to determine which were grammatical (and therefore more likely to be accepted and propagated by internet communities) and which were not.

.jpg)
.jpg)